
Демо глубокого обучения для обнаружения опухолей печени при КТ-сканировании
Автор: Джулия Гонг, студентка второго курса Стэнфордского университета, специальность «Математика и вычислительная наука», «Лингвистика»
Это пятый и последний пост в моей серии постов о модели глубокого обучения, которую я разработала для обнаружения опухолей в 3D КТ-сканировании печени. Мой последний пост был о визуализации результатов проекта компьютерного зрения. Этот пост будет посвящен точности модели и финальной демонстрации проекта.
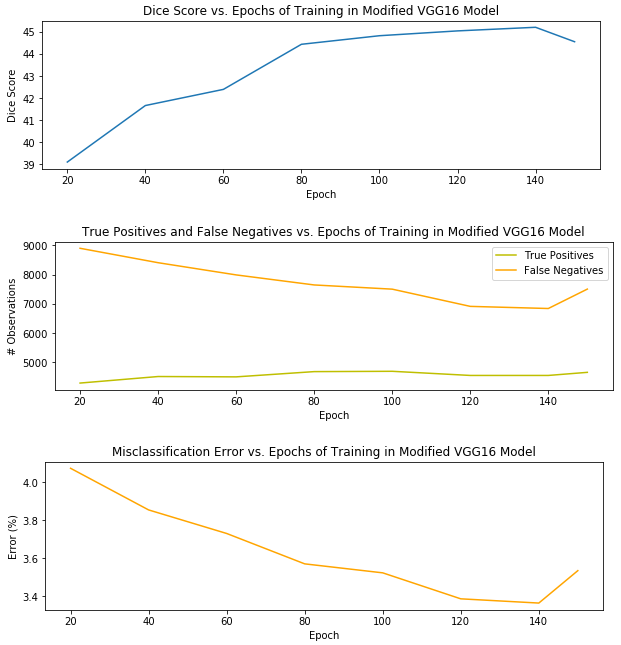
Без множества доработок модели или пост-обработки сегментации версия моего пайплайна с наилучшей производительностью сегментации использовала модель VGG16, которая была обучена 140 эпохам и показала оценку Dice 45,20%. Я объясню метрику оценки Dice через минуту. До этого я хотела бы представить визуальную характеристику модели на тестовом наборе, который используется для честной оценки модели во время обучения - более 150 эпох обучения.
Понятно, что переоснащение стало происходить в 150 эпохах, когда неправильная классификация и ложные срабатывания снова начали подкрадываться, и оценка Dice начала уменьшаться. Таким образом, я выбрала модель после 140 эпох как лучший вариант для пайплайна.
Архитектура модели глубокого обучения
Что такое оценка Dice?
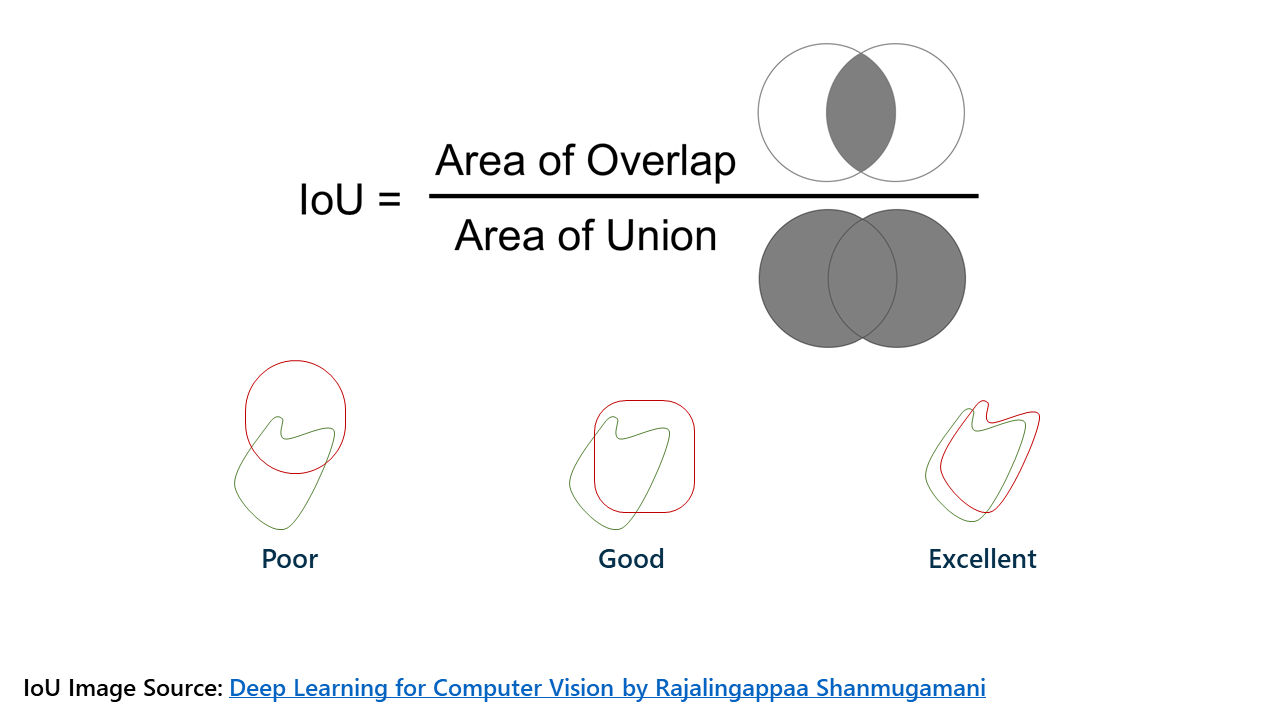
Оценка Dice, также известная как пересечение между двумя обнаружениями, является способом описания точности результатов машинного обучения. Самый простой способ описать это с помощью диаграммы Венна.
Левый кружок - это группа пикселей, которые следует классифицировать как имеющие поражение; правый кружок - это группа пикселей, которую модель фактически классифицировала как поражение. Область перекрытия в идеале очень большая, это означает, что модель классифицировала поражения как поражения. Левая сторона диаграммы Венна представляет ложно отрицательные результаты или участки с поражениями, которые должны были быть классифицированы как поражения, но не были; правая сторона представляет ложно положительные результаты или участки без поражений, которые были классифицированы как поражение, но не должны были.
Оценка Dice является более строгим критерием точности модели, чем ошибочная классификация, так как она не заботится об истинных ложно отрицательных результатах, которые могут быть на большинстве участков (те, которые не должны быть классифицированы как поражение и не были). Оценка Dice в 45,20% без слишком большого количества доработок пайплайна является очень многообещающей, так как современная оценка Dice с использованием этого подхода составляет около 60%!
Представление результатов модели
Когда пришло время представить результаты, мне повезло, что в зале присутствовал не только мой менеджер и наставник, но и руководители SAS и специалисты по машинному обучению. Я рассказала о мотивации проекта и его значении, представила обзор и углубилась в код моего блокнота на Jupyter.
Я также представила краткое резюме основных моментов проекта, в том числе:
- Построение модели с точностью оценки Dice - 45,20% при сегментации поражения печени в 3D КТ сканировании без уточнений или сегментации печени и в ограниченной предварительной обработке.
- Сквозной автоматизированный пайплайн обработки и анализа данных, что закладывает основу для будущей биомедицинской аналитики изображений в SAS® Viya.
- Самые первые возможности CAS были тщательно протестированы и применены к задаче с большими объемами данных.
- Одно из первых крупномасштабных приложений SAS Viya для глубокого обучения для анализа биомедицинских изображений на реальных данных.
- Первый раз, когда я коснулась глубокого обучения, создания пайплайнов данных, программирования на стороне сервера, базы данных или программирования на GPU.
- Манипулирование данными в памяти в CAS, демонстрируя силу и автономность CAS.
- Генерация списка требований для улучшений и дополнительных функций в CAS и Viya, а также возможный DLPy и другие материалы API.
- Работа с данными партнера SAS и иллюстрирование возможностей SAS Viya, чтобы упорядочить беспорядочные данные и решить проблемы реального мира.
Дальнейшие улучшения в пайплайне проекта включают в себя внедрение U-Net и 3D свертки вместо метода скользящего окна, а также постобработку и выравнивание сегментации с использованием условных случайных полей и RNN или LSTM для включения третьего измерения контекста из соседних срезов.
Во время презентации руководители и члены моей команды задавали вопросы и предлагали мне задуматься над фреймворками, которые я разработала, и более подробно объяснить мотивы выбора дизайна, который я сделала. Это интеллектуально стимулировало меня и заставило жаждать новых возможностей для привнесения значимого вклада в промышленность и мир в целом благодаря своим увлечениям.
В восторге от продолжения изучения
Это был захватывающий опыт - не только выполнить работу, но и представить ее экспертам и лидерам отрасли в области аналитики, а также тем, кто не был знаком с компьютерным зрением. Возможность представить этот проект и техническую информацию одновременно многим людям с различным бэкграундом и интересами было сложно, но очень полезно.
Я обнаружила, что публичные выступления, машинное обучение и технологии, применимые к проблемам реального мира, определенно становятся одними из моих увлечений. Благодаря этому проекту я изучила многое и выросла как "обучатель" машин, программист, agile scrummer и любитель глубокого обучения для биомедицинской аналитики изображений. Я невероятно взволнована тем, что нас ждет в будущем, и я очень благодарна SAS и моим наставникам за то, что вложили в меня много знаний.
И, оказывается, мне нравится писать статьи о технологиях. Посмотрите мою ИИ-демистифицирующую статью и пост в блоге SAS Life, где я даю советы, как максимально использовать вашу стажировку. Следите за обновлениями и не стесняйтесь связываться со мной. До следующей встречи, мои друзья по аналитике...
ОБ АВТОРЕ
Джулия Гонг - второкурсница в Стэнфордском университете, специальность «Математика и вычислительная наука», «Лингвистика». Она начала работать в SAS летом 2016 года, когда она создала программное обеспечение для обнаружения рака кожи на JMP с использованием методов анализа изображений и статистического моделирования. Летом 2017 года она использовала язык сценариев JMP для создания интерактивного пользовательского компоновщика R-надстроек для JMP. Летом 2018 года она создала сквозной автоматизированный пайплайн данных для сегментации опухолей печени при 3D-КТ-сканировании с использованием глубокого обучения и компьютерного зрения для анализа биомедицинских изображений в SAS Viya и CAS. Она получила признание на международных технологических конкурсах; любит публичные выступления, и ей нравится искать новые решения в таких областях, как искусственный интеллект, машинное обучение, лингвистика, охрана окружающей среды, медицина, сервис и искусство. Джулия надеется продолжить карьеру, которая объединит ее многочисленные интересы в области компьютерного зрения, искусственного интеллекта, медицины, обработки естественного языка, социального блага, образования и жизнеспособности.
Рекомендуем прочитать
-
 Ключевые вопросы для запуска ваших проектов по аналитике данныхНет единого плана по работе над проектом по аналитике данных. Эксперт по технологиям Фил Саймон предлагает рассмотреть эти десять вопросов в качестве руководства.
Ключевые вопросы для запуска ваших проектов по аналитике данныхНет единого плана по работе над проектом по аналитике данных. Эксперт по технологиям Фил Саймон предлагает рассмотреть эти десять вопросов в качестве руководства.
-
 Viking transforms its analytics strategy using SAS® Viya® on AzureViking is going all-in on cloud-based analytics to stay competitive and meet customer needs. The retailer's digital transformation are designed to optimize processes and boost customer loyalty and revenue across channels.
Viking transforms its analytics strategy using SAS® Viya® on AzureViking is going all-in on cloud-based analytics to stay competitive and meet customer needs. The retailer's digital transformation are designed to optimize processes and boost customer loyalty and revenue across channels.
-
 Public health infrastructure desperately needs modernizationPublic health agencies must flex to longitudinal health crises and acute emergencies – from natural disasters like hurricanes to events like a pandemic. To be prepared, public health infrastructure must be modernized to support connectivity, real-time data exchanges, analytics and visualization.
Public health infrastructure desperately needs modernizationPublic health agencies must flex to longitudinal health crises and acute emergencies – from natural disasters like hurricanes to events like a pandemic. To be prepared, public health infrastructure must be modernized to support connectivity, real-time data exchanges, analytics and visualization.