
Доработка модели глубокого обучения для обнаружения объектов
Автор: Джулия Гонг, студентка второго курса Стэнфордского университета, специальность «Математика и вычислительная наука», «Лингвистика»
Это четвертый пост в моей серии публикаций о проекте компьютерного зрения, над которым я работала, чтобы идентифицировать опухоли печени при КТ-сканировании. В моем предыдущем посте я отошла от работы над моделью глубокого обучения, чтобы поработать над управлением данными и маркировкой данных.
Теперь я возвращаюсь к модели и стараюсь улучшить ее для достижения лучших результатов. На этом этапе проекта мне был предоставлен доступ к кластеру графических процессоров в SAS, который позволил мне обучать модели с гораздо более высокими скоростями, давая мне возможность тестировать больше параметров за меньшее время.
Я избавлю вас от кровавых подробностей (не стесняйтесь связаться со мной, если вы хотите что-то обсудить), но, в конце концов, я выбрала модель VGG16 с модификациями для полностью подключенных слоев, где добавила коэффициент отсева 0,5 в надежде предотвратить перенастройку, что происходит, когда модель слишком хорошо запоминает тренировочные данные и не может хорошо работать с новыми данными, которые она видит позже.
Для изучающих глубокое обучение, вот архитектура модели:
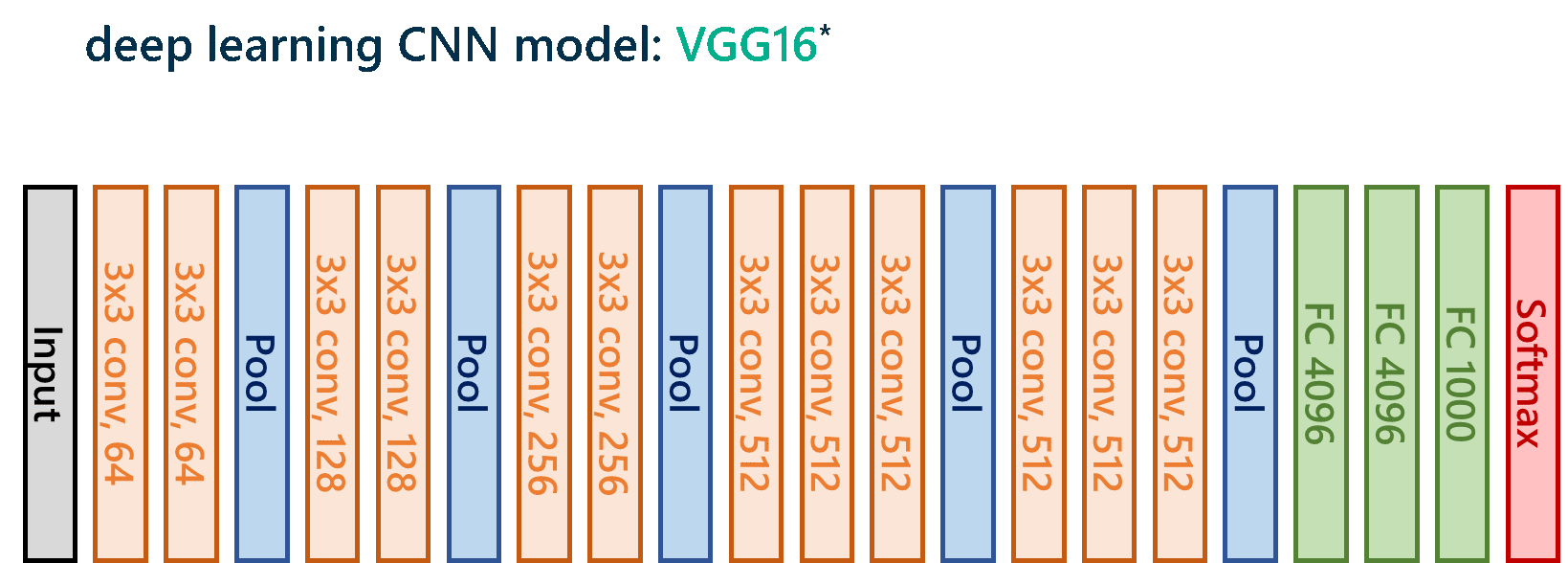
Архитектура модели глубокого обучения
3D визуализация результатов сегментации
Как только модель классифицирует все участки в данном 3D-КТ-скане, следующим шагом будет сборка результатов во что-то визуальное. Итак, последний шаг в пайплайне - это получение тех необработанных результатов классификации из модели VGG16 и использование SAS для визуализации в трехмерном пространстве сегментированных повреждений, которые определила сеть.
После переноса рядов пиксельных классификаций, определенных моделью, в одну строку, представляющую собой линеаризованное плоское изображение, этот ряд пикселей уплотняется в 2D-изображение, которое визуализирует результат сегментации конкретного среза при КТ-сканировании. Как только это будет сделано для каждого из 2D срезов в данном сканировании, у нас будут результаты сегментации всего сканирования. Полученный результат в идеале должен выглядеть примерно как данная рентгенологом классификация:

Вот пример результата из реального пайплайна, если посмотреть через нашего хорошего друга Python MayaVi:

Я считаю эту визуализацию невероятно классной (и подтверждающей подлинность). Она так сильно отличается от простого взгляда на линейные метрики производительности модели, и это просто увлекательно!
К счастью для меня, мне удалось завершить эту 3D-визуализацию перед финальной демонстрацией моего проекта. Потратив много времени на прочесывание всех моих ноутбуков Jupyter, которые содержали различные фрагменты пайплайна, и компиляции кода, иллюстрирующего полную сквозную систему, я была более чем когда-либо рада представить свою работу!
Я расскажу вам все об этой финальной презентации и точности модели в моем следующем посте.
ОБ АВТОРЕ
Джулия Гонг - второкурсница в Стэнфордском университете, специальность «Математика и вычислительная наука», «Лингвистика». Она начала работать в SAS летом 2016 года, когда она создала программное обеспечение для обнаружения рака кожи на JMP с использованием методов анализа изображений и статистического моделирования. Летом 2017 года она использовала язык сценариев JMP для создания интерактивного пользовательского компоновщика R-надстроек для JMP. Летом 2018 года она создала сквозной автоматизированный пайплайн данных для сегментации опухолей печени при 3D-КТ-сканировании с использованием глубокого обучения и компьютерного зрения для анализа биомедицинских изображений в SAS Viya и CAS. Она получила признание на международных технологических конкурсах; любит публичные выступления, и ей нравится искать новые решения в таких областях, как искусственный интеллект, машинное обучение, лингвистика, охрана окружающей среды, медицина, сервис и искусство. Джулия надеется продолжить карьеру, которая объединит ее многочисленные интересы в области компьютерного зрения, искусственного интеллекта, медицины, обработки естественного языка, социального блага, образования и жизнеспособности.
Рекомендуем прочитать
-
 What is synthetic data? And how can you use it to fuel AI breakthroughs?There's no shortage of data in today's world, but it can be difficult, slow and costly to access sufficient high-quality data that’s suitable for training AI models. Learn why synthetic data is so vital for data-hungry AI initiatives, how businesses can use it to unlock growth, and how it can help address ethical challenges.
What is synthetic data? And how can you use it to fuel AI breakthroughs?There's no shortage of data in today's world, but it can be difficult, slow and costly to access sufficient high-quality data that’s suitable for training AI models. Learn why synthetic data is so vital for data-hungry AI initiatives, how businesses can use it to unlock growth, and how it can help address ethical challenges.
-
 Public health infrastructure desperately needs modernizationPublic health agencies must flex to longitudinal health crises and acute emergencies – from natural disasters like hurricanes to events like a pandemic. To be prepared, public health infrastructure must be modernized to support connectivity, real-time data exchanges, analytics and visualization.
Public health infrastructure desperately needs modernizationPublic health agencies must flex to longitudinal health crises and acute emergencies – from natural disasters like hurricanes to events like a pandemic. To be prepared, public health infrastructure must be modernized to support connectivity, real-time data exchanges, analytics and visualization.
-
 What is omnichannel analytics?Умные ритейлеры понимают, что сегодня для успешного бизнеса одного лишь маркетинга уже недостаточно
What is omnichannel analytics?Умные ритейлеры понимают, что сегодня для успешного бизнеса одного лишь маркетинга уже недостаточно