
Построение передней части пайплайна компьютерного зрения
Автор: Джулия Гонг, студентка второго курса Стэнфордского университета, специальность «Математика и вычислительная наука», «Лингвистика»
Это третий пост, описывающий проект компьютерного зрения, над которым я работала в SAS для выявления опухолей печени при КТ-сканировании. В моем предыдущем посте я говорила о тестировании различных моделей и гиперпараметрах для моделей. Сегодня я расскажу об обработке данных для данных изображений. Если вам нужно наверстать упущенное, прочитайте мои предыдущие посты здесь.
Где-то на полпути моего проекта я поняла, что мне нужно на время оставить модели глубокого обучения в одиночестве, чтобы я могла вернуться к ним позже со свежим взглядом. А в это время я хотела бы заняться предварительной обработкой и последующей обработкой данных, чтобы завершить пайплайн с двух сторон базовой модели.
Первым шагом в пайплайне обработки данных является получение необработанного изображения, увеличение его контраста путем выравнивания гистограммы, его обрезки до соответствующего размера и добавление к нему со всех сторон по 128 пикселей (я объясню это чуть позже), а также генерация участков со всех сторон. Эти участки нужны для превращения этой задачи сегментации в задачу классификации.
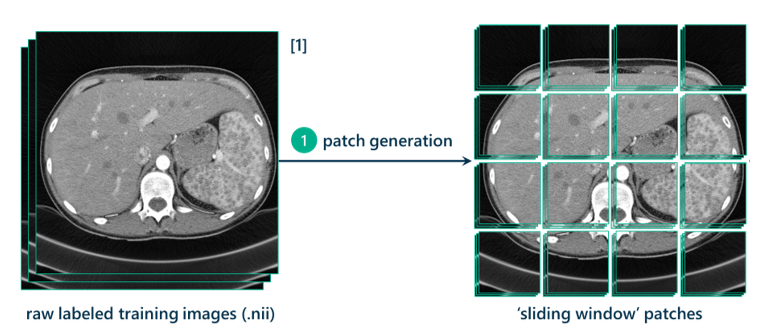
Генерация участков в скользящем окне для обнаружения объектов
Метод, который я использую, называется методом скользящего окна (sliding window). Этот подход требует работы с 3D КТ-сканированием в виде сотен 2D-срезов. Каждый срез будет использоваться для создания тысяч участков размером 257x257 пикселей для использования в качестве обучающих данных. Методом генерации этих участков является расширение квадрата размером 257x257 пикселей по исходному изображению размером с шаг на определенное количество пикселей (в данном случае 7). Каждый седьмой пиксель генерирует участок.
Маркировка результатов
Вот где появляется компонент классификации. Каждому участку будет присвоен ярлык: повреждение или отсутствие повреждения. Участок считается поврежденным, если средний пиксель этого участка находится внутри поражения в сегментированных вручную надежных черно-белых сканированиях, которые были аннотированы рентгенологами. Если пиксель белый, метка является повреждением. Если нет, то это участок без повреждений.
Я дополнила изображение со всех четырех сторон на черном фоне, чтобы предотвратить потерю информации. Поскольку мы классифицируем только участки на основе среднего пикселя, это позволяет каждому пикселю на скане быть средним пикселем одного из этих участков и классифицироваться в обучающих данных:
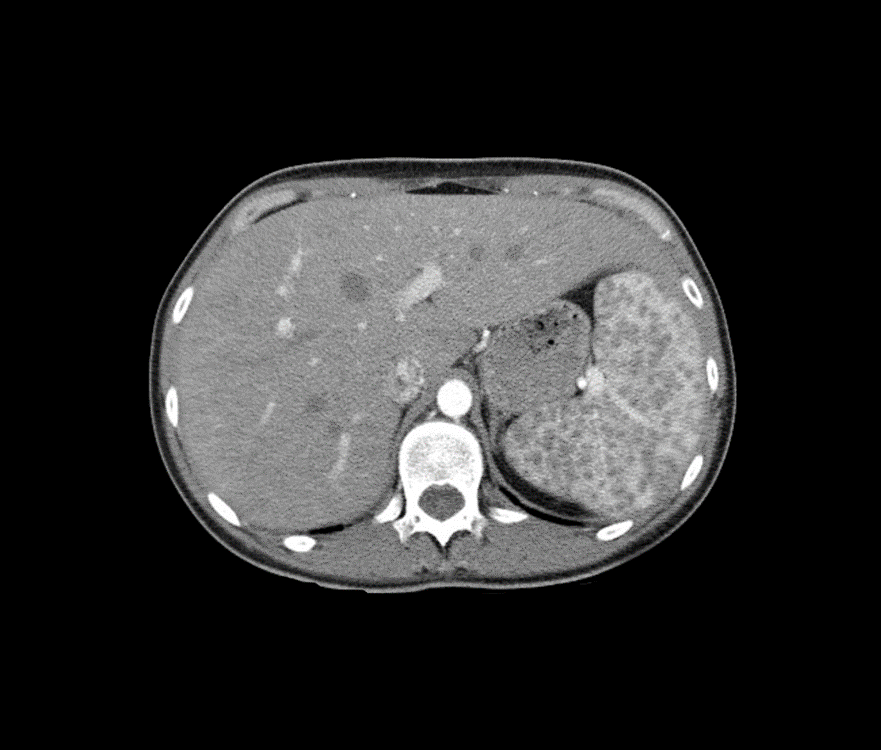
КТ-сканирование с добавлением по сторонам
Теперь, когда у нас есть наши участки, рекомендуется расширять их, чтобы генерировать еще больше данных для обучения модели. Это означает, что нужно копировать участки и настраивать их различными способами, увеличивая контраст, осветляя, затемняя, вращая, обрезая, переворачивая, обостряя или размывая. Расширение данных позволяет модели быть более устойчивой к возможным изменениям данных, на которых будет тестироваться модель, что, как мы надеемся, приведет к созданию более надежной, трансферной и адаптируемой модели.
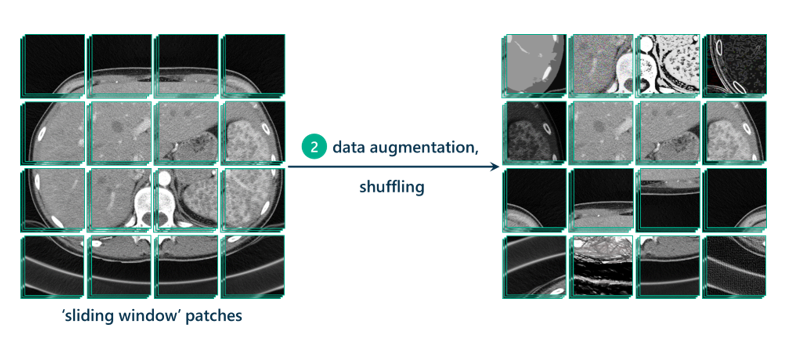
Перетаскивание участков
Отбор несоответствующих данных
Еще один шаг, прежде чем эти данные будут введены в модель: нам необходимо устранить несоответствие данных. Как вы, возможно, уже поняли, участков без повреждений гораздо больше, чем с повреждениями. На самом деле это соотношение составляет около 50:1. Из-за такого огромного дисбаланса сеть может с трудом подобрать правильные характеристики, которые характеризуют участки повреждения. Таким образом, мне нужно было отобрать участки без повреждений, чтобы скорректировать это соотношение до чего-то более разумного.
С эвристической точки зрения, я выбрала 2:1, поскольку казалось, что 1:1 может привести к неправильному представлению образцов без повреждений, но что-то более высокое может снова привести к дисбалансу. Я получила около 122 000 участков в соотношении 2:1, чтобы тренировать мою модель.
Дождитесь моего следующего поста, где я возвращаюсь к модели глубокого обучения со свежим взглядом.
ОБ АВТОРЕ
Джулия Гонг - второкурсница в Стэнфордском университете, специальность «Математика и вычислительная наука», «Лингвистика». Она начала работать в SAS летом 2016 года, когда она создала программное обеспечение для обнаружения рака кожи на JMP с использованием методов анализа изображений и статистического моделирования. Летом 2017 года она использовала язык сценариев JMP для создания интерактивного пользовательского компоновщика R-надстроек для JMP. Летом 2018 года она создала сквозной автоматизированный пайплайн данных для сегментации опухолей печени при 3D-КТ-сканировании с использованием глубокого обучения и компьютерного зрения для анализа биомедицинских изображений в SAS Viya и CAS. Она получила признание на международных технологических конкурсах; любит публичные выступления, и ей нравится искать новые решения в таких областях, как искусственный интеллект, машинное обучение, лингвистика, охрана окружающей среды, медицина, сервис и искусство. Джулия надеется продолжить карьеру, которая объединит ее многочисленные интересы в области компьютерного зрения, искусственного интеллекта, медицины, обработки естественного языка, социального блага, образования и жизнеспособности.
Рекомендуем прочитать
-
 Big data in government: How data and analytics power public programsBig data in government is vital when analyzed and used to improve the outcomes of both public and private sector programs – from emergency response to workforce effectiveness. The vast volumes of data created every day are the foundation of insightful changes for government agencies across the globe.
Big data in government: How data and analytics power public programsBig data in government is vital when analyzed and used to improve the outcomes of both public and private sector programs – from emergency response to workforce effectiveness. The vast volumes of data created every day are the foundation of insightful changes for government agencies across the globe.
-
 Fraud detection and machine learning: What you need to knowМашинное обучение является важной частью инструментария обнаружения мошенничества. Вот что вам нужно для начала работы.
Fraud detection and machine learning: What you need to knowМашинное обучение является важной частью инструментария обнаружения мошенничества. Вот что вам нужно для начала работы.
-
 The importance of data quality: A sustainable approachBad data wrecks countless business ventures. Here’s a data quality plan to help you get it right.
The importance of data quality: A sustainable approachBad data wrecks countless business ventures. Here’s a data quality plan to help you get it right.