UNIVARIATEプロシジャ
- 概要
-
入門ガイド

-
構文
-
詳細
欠損値 丸め 記述統計量 モードの計算 パーセント点の計算 位置の検定 正規分布のパラメータに対する信頼限界 ロバスト推定量 ラインプリンタプロットの作成 高解像度グラフの作成 CLASSステートメントを使用した比較プロットの作成 インセットの配置 当てはめた連続分布の計算式 適合度検定 核密度推定 Q-Qプロットと確率プロットの作成 Q-Qプロットと確率プロットの解釈 確率プロットとQ-Qプロットの分布 Q-Qプロットを使用した形状パラメータの推定 Q-Qプロットを使用した位置パラメータと尺度パラメータの推定 Q-Qプロットを使用したパーセント点の推定 入力データセット OUTPUTステートメントのOUT=出力データセット OUTHISTOGRAM=出力データセット OUTKERNEL=出力データセット OUTTABLE=出力データセット 要約統計量のテーブル ODSテーブル名 当てはめた分布のODSテーブル ODS Graphics 計算リソース
-
例
複数の変数に対する記述統計量の計算 モードの計算 極値のオブザベーションと極値の表示 度数表の作成 ラインプリンタ出力プロットの作成 FREQ変数を使用したデータセットの分析 OUT=出力データセットへの要約統計量の保存 出力データセットへのパーセント点の保存 平均、標準偏差、分散に対する信頼限界の計算 分位点とパーセント点に対する信頼限界の計算 ロバスト推定の計算 位置の検定 対応のあるデータを使用した符号検定の実行 ヒストグラムの作成 一元比較ヒストグラムの作成 二元比較ヒストグラムの作成 記述統計量を含むインセットの追加 ヒストグラムのビン幅の指定 正規曲線をヒストグラムに追加する 当てはめた正規曲線を比較ヒストグラムに追加する ベータ曲線の当てはめ 対数正規曲線、Weibull曲線、ガンマ曲線の当てはめ 核密度推定の計算 3パラメータ対数正規曲線の当てはめ 折り重ねられた正規曲線の追加表示 対数正規確率プロットの作成 対数正規分布の当てはめを表示するヒストグラムの作成 正規確率プロットの作成 分布の参照線の追加 正規確率プロットの解釈 対数正規確率プロットから3パラメータを推定する 対数正規確率プロットからパーセント点を推定する 対数正規確率プロットからパラメータを推定する Weibull分布の分位点プロットの比較 累積分布プロットの作成 P-Pプロットの作成
- リファレンス
| 位置の検定 |
PROC UNIVARIATEでは、スチューデントの 検定、符号検定およびWilcoxonの符号付き順位検定の3つの位置の検定を行うことができます。3つの検定はすべて、平均値または中央値が
検定、符号検定およびWilcoxonの符号付き順位検定の3つの位置の検定を行うことができます。3つの検定はすべて、平均値または中央値が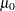 に等しくない両側対立仮説に対する、平均値または中央値が指定した値に等しい帰無仮説の検定統計量を作成します。デフォルトでは、PROC UNIVARIATEはの値を0に設定します。PROC UNIVARIATEステートメントのMU0=オプションを使用して、の値を指定できます。スチューデントの検定は、母集団が正規分布に近いデータの場合に適しています。それ以外の場合は、符号検定や符号付き順位検定などのノンパラメトリックな検定を使用します。母集団が大きい場合、検定は漸近的に
に等しくない両側対立仮説に対する、平均値または中央値が指定した値に等しい帰無仮説の検定統計量を作成します。デフォルトでは、PROC UNIVARIATEはの値を0に設定します。PROC UNIVARIATEステートメントのMU0=オプションを使用して、の値を指定できます。スチューデントの検定は、母集団が正規分布に近いデータの場合に適しています。それ以外の場合は、符号検定や符号付き順位検定などのノンパラメトリックな検定を使用します。母集団が大きい場合、検定は漸近的に 検定と同等になります。WEIGHTステートメントを使用すると、PROC UNIVARIATEは位置の重み付き検定である検定を1つだけ計算します。PROCステートメントのVARDEF=オプションのデフォルト値(VARDEF=DF)を使用する必要があります。例4.12を参照してください。
検定と同等になります。WEIGHTステートメントを使用すると、PROC UNIVARIATEは位置の重み付き検定である検定を1つだけ計算します。PROCステートメントのVARDEF=オプションのデフォルト値(VARDEF=DF)を使用する必要があります。例4.12を参照してください。
また、これらの検定を使用して、対応のあるデータの平均値または中央値を比較できます。同じ年齢と性別を持つサブジェクトなど、一対のサブジェクトやユニットが1つ以上の変数を基準に一致している場合、データは対応していると言います。対応のあるデータは、各サブジェクトまたはユニットが2回測定される場合や、2つの条件で測定される場合にも出現します。2回の平均値または中央値を比較するには、2つの指標の間の差である分析変数を作成します。変数の平均値または中央値の差が0に等しい検定は、2つの元の変数の平均値または中央値が等しい検定と同じです。これらの検定は、TTESTプロシジャのPAIREDステートメントを使用して実行することもできます。Chapter 95, The TTEST Procedure (SAS/STAT User's Guide)を参照してください。また、例4.13を参照してください。
スチューデントのt検定
PROC UNIVARIATEは、統計量を次のように計算します。
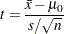 |
 は標本平均、
は標本平均、 は変数の非欠損値の数、
は変数の非欠損値の数、 は標本標準偏差です。帰無仮説は、母集団平均がに等しいことです。データ値が正規分布に近似している場合、帰無仮説下の統計量が極端である、つまり観測値よりも極端となる確率(
は標本標準偏差です。帰無仮説は、母集団平均がに等しいことです。データ値が正規分布に近似している場合、帰無仮説下の統計量が極端である、つまり観測値よりも極端となる確率(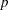 値)は、自由度が
値)は、自由度が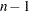 の分布から取得されます。が大きい場合、統計量は漸近的に検定と同等になります。WEIGHTステートメントとVARDEF=のデフォルト値(DF)を使用するとき、統計量は次のように計算されます。
の分布から取得されます。が大きい場合、統計量は漸近的に検定と同等になります。WEIGHTステートメントとVARDEF=のデフォルト値(DF)を使用するとき、統計量は次のように計算されます。
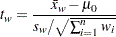 |
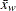 は重み付き平均、
は重み付き平均、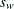 は重み付き標準偏差、
は重み付き標準偏差、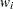 は
は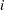 番目のオブザベーションの重みです。
番目のオブザベーションの重みです。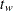 統計量は、自由度がのスチューデントの分布として扱われます。PROCステートメントでEXCLNPWGTオプションを指定する場合、はWEIGHT変数が正のときの非欠損オブザベーションの数です。デフォルトでは、はWEIGHT変数の非欠損オブザベーションの数です。
統計量は、自由度がのスチューデントの分布として扱われます。PROCステートメントでEXCLNPWGTオプションを指定する場合、はWEIGHT変数が正のときの非欠損オブザベーションの数です。デフォルトでは、はWEIGHT変数の非欠損オブザベーションの数です。
符号検定
PROC UNIVARIATEは、符号検定統計量を次のように計算します。
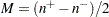 |
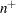 はより大きい値の数、
はより大きい値の数、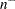 はより小さい値の数です。に等しい値は破棄されます。母集団中央値がに等しいという帰無仮説のもとで、観測された統計量
はより小さい値の数です。に等しい値は破棄されます。母集団中央値がに等しいという帰無仮説のもとで、観測された統計量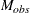 の値は次のようになります。
の値は次のようになります。
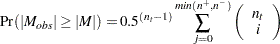 |
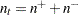 はに等しくない
はに等しくない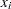 値の数です。
値の数です。
注: とが等しい場合、値は1です。
Wilcoxonの符号付き順位検定
符号付き順位統計量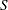 は次のように計算されます。
は次のように計算されます。
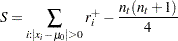 |
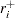 は
は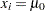 の値を破棄した後の
の値を破棄した後の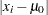 の順位、
の順位、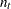 はに等しくない値の数です。結合された値には平均順位が使用されます。
はに等しくない値の数です。結合された値には平均順位が使用されます。
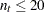 の場合、の有意性はの厳密分布から計算されます。この分布は調整された二項分布の畳み込みです。
の場合、の有意性はの厳密分布から計算されます。この分布は調整された二項分布の畳み込みです。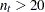 の場合、の有意性の計算は次のように行います。
の場合、の有意性の計算は次のように行います。
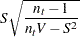 |
これを自由度が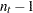 のスチューデントの変量として扱うことによって、優位性が計算されます。
のスチューデントの変量として扱うことによって、優位性が計算されます。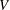 は次のように計算されます。
は次のように計算されます。
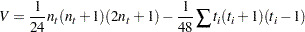 |
この合計は絶対値がタイのグループの合計です。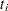 は、番目のグループの値の数です(Iman; 1974; Conover; 1999)。分布が対称であると仮定して、平均値(または中央値)がであるという帰無仮説が検定されます。Lehmann (1998)を参照してください。
は、番目のグループの値の数です(Iman; 1974; Conover; 1999)。分布が対称であると仮定して、平均値(または中央値)がであるという帰無仮説が検定されます。Lehmann (1998)を参照してください。