UNIVARIATEプロシジャ
- 概要
-
入門ガイド

-
構文
-
詳細
欠損値 丸め 記述統計量 モードの計算 パーセント点の計算 位置の検定 正規分布のパラメータに対する信頼限界 ロバスト推定量 ラインプリンタプロットの作成 高解像度グラフの作成 CLASSステートメントを使用した比較プロットの作成 インセットの配置 当てはめた連続分布の計算式 適合度検定 核密度推定 Q-Qプロットと確率プロットの作成 Q-Qプロットと確率プロットの解釈 確率プロットとQ-Qプロットの分布 Q-Qプロットを使用した形状パラメータの推定 Q-Qプロットを使用した位置パラメータと尺度パラメータの推定 Q-Qプロットを使用したパーセント点の推定 入力データセット OUTPUTステートメントのOUT=出力データセット OUTHISTOGRAM=出力データセット OUTKERNEL=出力データセット OUTTABLE=出力データセット 要約統計量のテーブル ODSテーブル名 当てはめた分布のODSテーブル ODS Graphics 計算リソース
-
例
複数の変数に対する記述統計量の計算 モードの計算 極値のオブザベーションと極値の表示 度数表の作成 ラインプリンタ出力プロットの作成 FREQ変数を使用したデータセットの分析 OUT=出力データセットへの要約統計量の保存 出力データセットへのパーセント点の保存 平均、標準偏差、分散に対する信頼限界の計算 分位点とパーセント点に対する信頼限界の計算 ロバスト推定の計算 位置の検定 対応のあるデータを使用した符号検定の実行 ヒストグラムの作成 一元比較ヒストグラムの作成 二元比較ヒストグラムの作成 記述統計量を含むインセットの追加 ヒストグラムのビン幅の指定 正規曲線をヒストグラムに追加する 当てはめた正規曲線を比較ヒストグラムに追加する ベータ曲線の当てはめ 対数正規曲線、Weibull曲線、ガンマ曲線の当てはめ 核密度推定の計算 3パラメータ対数正規曲線の当てはめ 折り重ねられた正規曲線の追加表示 対数正規確率プロットの作成 対数正規分布の当てはめを表示するヒストグラムの作成 正規確率プロットの作成 分布の参照線の追加 正規確率プロットの解釈 対数正規確率プロットから3パラメータを推定する 対数正規確率プロットからパーセント点を推定する 対数正規確率プロットからパラメータを推定する Weibull分布の分位点プロットの比較 累積分布プロットの作成 P-Pプロットの作成
- リファレンス
| 記述統計量 |
このセクションでは、PROC UNIVARIATEステートメントで計算される記述統計量の計算の詳細を示します。これらの統計量は、OUTPUTステートメントで表4.60にあるキーワードを指定することにより、OUT=データセットに保存することもできます。
標準アルゴリズム(Fisher; 1973)は、積率統計量の計算に使用されます。UNIVARIATEプロシジャで使用される計算方法は、他のSASプロシジャで記述統計量の計算に使用される計算方法との間に一貫性があります。
次のセクションでは、UNIVARIATEプロシジャで計算されるいくつかの統計量の詳細を示します。
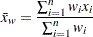
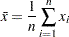
合計
合計は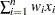 で計算されます。
で計算されます。 は変数の非欠損値の数、
は変数の非欠損値の数、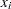 は変数の
は変数の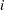 番目の値、
番目の値、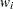 は変数の番目の値に関連付けられた重みです。WEIGHT変数が存在しない場合、この式は
は変数の番目の値に関連付けられた重みです。WEIGHT変数が存在しない場合、この式は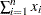 に短縮します。
に短縮します。
重みの合計
重みの合計は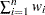 で計算されます。は変数の非欠損値の数、は変数の番目の値に関連付けられた重みです。WEIGHT変数が存在しない場合、重みの合計はです。
で計算されます。は変数の非欠損値の数、は変数の番目の値に関連付けられた重みです。WEIGHT変数が存在しない場合、重みの合計はです。
分散
分散は次のように計算されます。
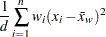 |
は変数の非欠損値の数、は変数の番目の値、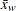 は重み付き平均、は変数の番目の値に関連付けられた重み、
は重み付き平均、は変数の番目の値に関連付けられた重み、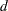 はPROC UNIVARIATEステートメントのVARDEF=オプションで制御される分母です。
はPROC UNIVARIATEステートメントのVARDEF=オプションで制御される分母です。
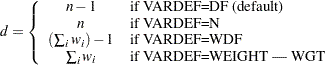 |
WEIGHT変数が存在しない場合、この式は次のようになる。
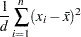 |
標準偏差
標準偏差は次のように計算されます。
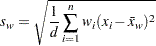 |
は変数の非欠損値の数、は変数の番目の値、は重み付き平均、は変数の番目の値に関連付けられた重み、はPROC UNIVARIATEステートメントのVARDEF=オプションで制御される分母です。WEIGHT変数が存在しない場合、この式は次のようになる。
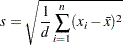 |
歪度
標本歪度は、偏差がある方向で他の方向より大きいという偏差の傾向を測定し、VARDEF=オプションに応じて次のように計算されます。
VARDEF |
公式 |
|---|---|
DF(デフォルト) |
|
N |
|
WDF |
欠損値 |
WEIGHT | WGT |
欠損値 |
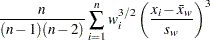
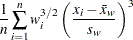
ここで、は変数の値が欠損値以外のオブザベーション数、は変数の番目の値、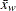 は標本平均、
は標本平均、 は標本標準偏差、は変数の番目の値に割り当てられる重みを表す VARDEF=DFの場合、は2より大きい必要があります。WEIGHT変数が存在しない場合、
は標本標準偏差、は変数の番目の値に割り当てられる重みを表す VARDEF=DFの場合、は2より大きい必要があります。WEIGHT変数が存在しない場合、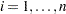 すべてで
すべてで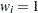 になります。
になります。
標本歪度は正または負の値になります。データ分布の非対称性を測定し、理論歪度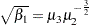 を推定します。
を推定します。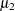 および
および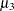 は2番目および3番目の中心積率です。オブザベーションが正規分布である場合、歪度は0に近くなります。
は2番目および3番目の中心積率です。オブザベーションが正規分布である場合、歪度は0に近くなります。
尖度
標本尖度は、標本の裾の重さを測定し、VARDEF=オプションに応じて次のように計算されます。
VARDEF |
公式 |
|---|---|
DF(デフォルト) |
|
N |
|
WDF |
欠損値 |
WEIGHT | WGT |
欠損値 |
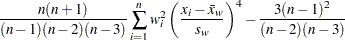
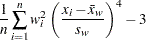
ここで、は変数の値が欠損値以外のオブザベーション数、は変数の番目の値、は標本平均、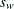 は標本標準偏差、は変数の番目の値に割り当てられる重みを表す VARDEF=DFの場合、は3より大きい必要があります。WEIGHT変数が存在しない場合、すべてでになります。
は標本標準偏差、は変数の番目の値に割り当てられる重みを表す VARDEF=DFの場合、は3より大きい必要があります。WEIGHT変数が存在しない場合、すべてでになります。
標本尖度はデータ分布の裾の重さを測定します。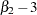 で示される調整された理論尖度を推定します。
で示される調整された理論尖度を推定します。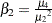 で、
で、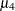 が4番目の中心積率です。オブザベーションが正規分布である場合、尖度は0に近くなります。
が4番目の中心積率です。オブザベーションが正規分布である場合、尖度は0に近くなります。
変動係数(CV)
変動計数は次のように計算されます。
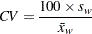 |