FREQプロシジャ

Jonckheere-Terpstra検定
TABLESステートメントでJTオプションを指定すると、クラス間の順序付き差異に関するノンパラメトリック検定であるJonckheere-Terpstra検定を実施できます。これは、応答変数の分布がクラス間で変化しないという帰無仮説を検定するものです。この検定は、順序付きのクラス差異に関する対立仮説を検出します。この対立仮説は、少なくとも1つの厳密な不等式を持つ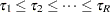 (または
(または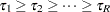 )として表されます。ここで、
)として表されます。ここで、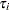 はクラス
はクラス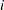 の効果を表します。このような順序付きの対立仮説の場合、Jonckheere-Terpstra検定の方が、Kruskal–Wallis検定(NPAR1WAYプロシジャのWILCOXONオプションにより実施されるもの)のような一般的なクラス差異に関する検定よりも適しています。Jonckheere-Terpstra検定に関する詳細は、Pirie (1983)およびHollander and Wolfe (1999)を参照してください。
の効果を表します。このような順序付きの対立仮説の場合、Jonckheere-Terpstra検定の方が、Kruskal–Wallis検定(NPAR1WAYプロシジャのWILCOXONオプションにより実施されるもの)のような一般的なクラス差異に関する検定よりも適しています。Jonckheere-Terpstra検定に関する詳細は、Pirie (1983)およびHollander and Wolfe (1999)を参照してください。
Jonckheere-Terpstra検定は、順序列変数が応答を表すような2元表に適しています。行変数(名義変数または順序変数のどちらでも構いません)は分類変数を表します。行変数の2つのレベルは、検定により検出させたい順序に従って順序付けされている必要があります。変数レベルの順序は、PROC FREQステートメントのORDER=オプションにより指定されます。デフォルトではORDER=INTERNALであり、フォーマットされていない値により順序付けが行われます。ORDER=DATAを指定すると、FREQプロシジャは、入力データセットの順序に従って値を並べかえます。 変数レベルの順序付け方法に関する詳細は、ORDER=オプションの説明を参照してください。
Jonckheere-Terpstra検定統計量を計算するには、まず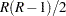 のMann-Whitneyカウントである
のMann-Whitneyカウントである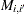 を形成します。ここで、
を形成します。ここで、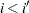 であり、分割表内の行のペアの場合は次のように表されます。
であり、分割表内の行のペアの場合は次のように表されます。
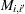 |
 |
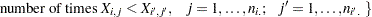 |
|||
 |
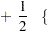 |
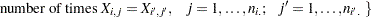 |
ここで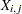 は、行
は、行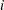 内の応答
内の応答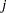 です。Jonckheere-Terpstra検定統計量は次のように計算されます。
です。Jonckheere-Terpstra検定統計量は次のように計算されます。
 |
この検定は、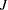 の値が大きい場合にはクラス間で差異がないという帰無仮説を拒否します。Jonckheere-Terpstra検定の漸近p値は、標準化された検定統計量の分布に対する正規近似を使用することにより導かれます。標準化された検定統計量は次のように計算されます。
の値が大きい場合にはクラス間で差異がないという帰無仮説を拒否します。Jonckheere-Terpstra検定の漸近p値は、標準化された検定統計量の分布に対する正規近似を使用することにより導かれます。標準化された検定統計量は次のように計算されます。
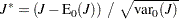 |
ここで、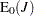 および
および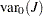 は、次の帰無仮説の下での検定統計量の期待値と分散になります。
は、次の帰無仮説の下での検定統計量の期待値と分散になります。
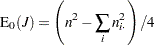 |
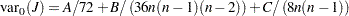 |
ここで、
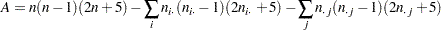 |
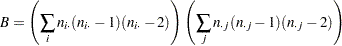 |
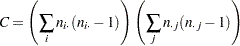 |
FREQプロシジャは、Jonckheere-Terpstra検定の片側および両側のp値を計算します。検定統計量がその帰無仮説の期待値ゼロよりも大きい場合、FREQプロシジャは右側値を表示します。これは、帰無仮説の下で統計量の大きな値が発生する確率になります。小さい右側p値は、行1から行 へと順序が上昇するという対立仮説を支持します。この標準化された検定統計量がゼロ以下である場合、FREQプロシジャは、左側p値を計算します。小さい左側pは、行1から行へと順序が下降するという対立仮説を支持します。
へと順序が上昇するという対立仮説を支持します。この標準化された検定統計量がゼロ以下である場合、FREQプロシジャは、左側p値を計算します。小さい左側pは、行1から行へと順序が下降するという対立仮説を支持します。
Jonckheere-Terpstra検定に関する片側p値 は、次のように計算されます。
は、次のように計算されます。
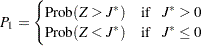 |
ここで、 は標準正規分布を持ちます。両側のp値
は標準正規分布を持ちます。両側のp値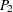 は次のように計算されます。
は次のように計算されます。
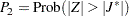 |
FREQプロシジャは、Jonckheere-Terpstra検定に関する正確なp値も計算します。この正確な検定を要求するには、EXACTステートメントでJTオプションを指定します。詳細は、正確な統計量のセクションを参照してください。