FREQプロシジャ

Cochran-Armitageの傾向検定
TABLESステートメントでTRENDオプションを指定すると、Cochran-Armitageの傾向検定を実施できます。これは、単一要因または共変量の水準を通じて二項比率の傾向を検定します。 この検定は、1つの変数が2つの水準を持ち、別の変数が順序変数であるような2元表に対して適用されます。2つの水準を持つ変数は応答変数を表し、別の変数は順序水準を持つ説明変数を表します。2元表が2つの列と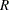 個の行を持つ場合、FREQプロシジャは、行変数の個の水準を通じて傾向を検定します。この結果、二項比率が、最初の列におけるオブザベーションの比率として計算されます。2元表が2つの行と
個の行を持つ場合、FREQプロシジャは、行変数の個の水準を通じて傾向を検定します。この結果、二項比率が、最初の列におけるオブザベーションの比率として計算されます。2元表が2つの行と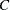 この列を持つ場合、FREQプロシジャは、列変数のこのレベルを通じて傾向を検定します。この結果、二項比率が、最初の行におけるオブザベーションの比率として計算されます。
この列を持つ場合、FREQプロシジャは、列変数のこのレベルを通じて傾向を検定します。この結果、二項比率が、最初の行におけるオブザベーションの比率として計算されます。
傾向検定は、説明変数水準のスコアにおいて、二項比率の重み付き線形回帰の回帰係数に基づいています。詳細は、Margolin (1988)およびAgresti (2002)を参照してください。表が2つの列と個の行を持つ場合、この傾向検定統計量は次のように計算されます。
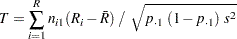 |
ここで、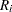 は行
は行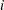 のスコア、
のスコア、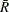 は平均の行スコアであり、次の式が成り立ちます。
は平均の行スコアであり、次の式が成り立ちます。
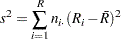 |
TABLESステートメントのSCORES=オプションは、傾向検定(およびその他のスコアに基づく統計量)の計算に使用される行スコアのタイプを指定します。デフォルトはSCORES=TABLEです。詳細は、スコアのセクションを参照してください。文字変数の場合、行変数の表スコアは行番号になります(すなわち、最初の行は1、2番目の行は2、という具合になります)。数値変数の場合、各行の表スコアは対応する行レベルの数値になります。傾向検定を実施する場合、説明変数は数値(披験物質の用量など)となり、その変数値は対応するスコアになります。説明変数が数値でない順序レベルを持つ場合、その変数レベルに対して有意なスコアを割り当てる必要があります。場合によっては、文字変数の表スコアのように、等間隔のスコアが適していることがあります。傾向検定におけるスコアの選択に関する詳細は、Margolin (1988)を参照してください。
Cochran-Armitage検定の帰無仮説は傾向がないことであり、これは二項比率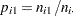 が説明変数のすべてのレベルで同じであることを意味します。帰無仮説の下では、傾向統計量は漸近標準正規分布に従います。
が説明変数のすべてのレベルで同じであることを意味します。帰無仮説の下では、傾向統計量は漸近標準正規分布に従います。
FREQプロシジャは、傾向検定の片側および両側のp値を計算します。検定統計量がその帰無仮説の期待値ゼロよりも大きい場合、FREQプロシジャは右側値を表示します。これは、帰無仮説の下で統計量の大きな値が発生する確率になります。小さい右側p値は、傾向の比率が行1から行へと上昇するという対立仮説を支持します。この検定統計量がゼロ以下である場合、FREQプロシジャは、左側p値を計算します。小さい左側p値は、傾向が減少するという対立仮説を支持します。
傾向検定に関する片側p値は次のように計算されます。
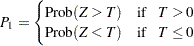 |
ここで、 は標準正規分布を持ちます。両側のp値は次のように計算されます。
は標準正規分布を持ちます。両側のp値は次のように計算されます。
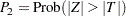 |
FREQプロシジャは、Cochran-Armitage傾向検定に関する正確なp値も計算します。この正確な検定を要求するには、EXACTステートメントでTRENDオプションを指定します。詳細は、正確な統計量のセクションを参照してください。