FREQプロシジャ

一致の検定と統計量
TABLESステートメントでAGREEオプションを指定すると、FREQプロシジャは、平方表(行数と列数が等しい表)の一致性に関する検定と統計量を計算します。2元表の場合、これらの検定および統計量としては、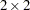 表に対するMcNemarの検定、Bowkerの対称性の検定、単純カッパ係数、重み付きカッパ係数が含まれます。複数の層がある場合(
表に対するMcNemarの検定、Bowkerの対称性の検定、単純カッパ係数、重み付きカッパ係数が含まれます。複数の層がある場合( 元表、ここで
元表、ここで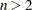 )、FREQプロシジャは、全体的な単純カッパ係数および重み付きカッパ係数の計算に加えて、各層間の(単純および重み付き)カッパ係数の同等性に対する検定も行います。多次元クロス表の各変数が2つのレベルを持つ場合(すなわち
)、FREQプロシジャは、全体的な単純カッパ係数および重み付きカッパ係数の計算に加えて、各層間の(単純および重み付き)カッパ係数の同等性に対する検定も行います。多次元クロス表の各変数が2つのレベルを持つ場合(すなわち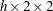 表の場合)、Cochranの
表の場合)、Cochranの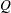 が計算されます。
が計算されます。
TABLESステートメントでAGREEオプションを指定すると、FREQプロシジャは、(単純および重み付き)カッパ係数、それらの漸近標準誤差、およびそれらの信頼限界を計算します。 TESTステートメントでKAPPAオプションを指定すると、FREQプロシジャは、単純カッパ係数がゼロに等しいという帰無仮説に関する漸近的な検定を計算します。同様に、TESTステートメントでWTKAPオプションを指定すると、FREQプロシジャは、重み付きカッパ係数に関する漸近的な検定を計算します。
このセクションで説明されている漸近検定に加えて、FREQプロシジャは、McNemarの検定、単純カッパ係数の検定、重み付きカッパ係数の検定に関する正確な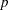 値も計算します これらの正確検定を要求するには、EXACTステートメントで対応するオプションを指定します。詳細は、正確な統計量のセクションを参照してください。
値も計算します これらの正確検定を要求するには、EXACTステートメントで対応するオプションを指定します。詳細は、正確な統計量のセクションを参照してください。
次のセクションでは、FREQプロシジャが各AGREE統計量の計算に使用する公式を示します。これらの統計量の解釈に関する詳細は、Agresti (2002)、Agresti (2007)、Fleiss, Levin, and Paik (2003)、および各統計量の説明で示されているリファレンスを参照してください。
McNemarの検定
AGREEオプションを指定すると、FREQプロシジャは、表に対するMcNemarの検定を計算します。McNemarの検定は、2値(yes/no式)応答を持つ一致したサブジェクトのペアからのデータを分析する場合に適しています。これは、周辺等質性に関する帰無仮説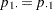 を検定するものです。McNemarの検定は次のように計算されます。
を検定するものです。McNemarの検定は次のように計算されます。
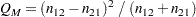 |
帰無仮説の下で、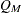 は自由度が1の漸近カイ2乗分布に従います。詳細は、McNemar (1947)および前出のリファレンスを参照してください。EXACTステートメントでMCNEMオプションを指定すると、FREQプロシジャは、漸近検定に加えて、McNemarの検定に関する正確な値も計算します。
は自由度が1の漸近カイ2乗分布に従います。詳細は、McNemar (1947)および前出のリファレンスを参照してください。EXACTステートメントでMCNEMオプションを指定すると、FREQプロシジャは、漸近検定に加えて、McNemarの検定に関する正確な値も計算します。
Bowkerの対称性の検定
Bowkerの対称性の検定では、セルの比率が対称であること、またはすべての表セルのペアで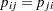 であることが帰無仮説となります。表の場合、Bowkerの検定はMcNemarの検定と同じになるため、FREQプロシジャは、より大きい平方表に対するBowkerの検定を計算します。
であることが帰無仮説となります。表の場合、Bowkerの検定はMcNemarの検定と同じになるため、FREQプロシジャは、より大きい平方表に対するBowkerの検定を計算します。
Bowkerの対称性の検定は次のように計算されます。
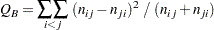 |
大きい標本の場合、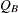 は、対称性に関する帰無仮説の下で自由度が
は、対称性に関する帰無仮説の下で自由度が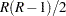 の漸近カイ2乗分布に従います。詳細はBowker (1948)を参照してください。
の漸近カイ2乗分布に従います。詳細はBowker (1948)を参照してください。
単純カッパ係数
単純カッパ係数とは、Cohen (1960)により導入された判定者間一致に関する指標です。FREQプロシジャは、単純カッパ係数を次のように計算します。
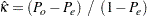 |
ここで、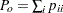 および
および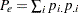 です。2つの応答変数が、個のサブジェクトに関する2つの独立した判定として認識される場合、それらの判定間に完全な一致が存在するならば、カッパ係数は+1に等しくなります。観測された一致性が偶然に一致する確率を超えている場合、カッパ係数は正数になり、その大きさは一致性の強度を反映します。実際にはあまり起こりませんが、観測された一致性が偶然に一致する確率よりも低い場合、カッパ係数は負数になります。カッパ係数の最小値は、周辺比率に応じて、
です。2つの応答変数が、個のサブジェクトに関する2つの独立した判定として認識される場合、それらの判定間に完全な一致が存在するならば、カッパ係数は+1に等しくなります。観測された一致性が偶然に一致する確率を超えている場合、カッパ係数は正数になり、その大きさは一致性の強度を反映します。実際にはあまり起こりませんが、観測された一致性が偶然に一致する確率よりも低い場合、カッパ係数は負数になります。カッパ係数の最小値は、周辺比率に応じて、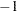 ~0の間になります。
~0の間になります。
単純カッパ係数の漸近分散は次のように計算されます。
 |
ここで、
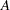 |
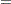 |
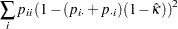 |
|||
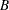 |
|
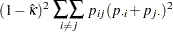 |
|||
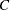 |
|
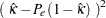 |
詳細は、Fleiss, Cohen, and Everitt (1969)を参照してください。
FREQプロシジャは、単純カッパ係数の信頼限界を次のように計算します。
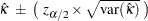 |
ここで、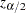 は標準正規分布の
は標準正規分布の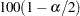 番目のパーセント点です。
番目のパーセント点です。 の値を指定するにはALPHA=オプションを使用します。この値はデフォルトで0.05であり、信頼限界は95%になります。
の値を指定するにはALPHA=オプションを使用します。この値はデフォルトで0.05であり、信頼限界は95%になります。
カッパ係数の漸近検定を計算する場合、FREQプロシジャは、標準化された検定統計量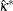 を使用します。この統計量は、カッパ係数がゼロであるという帰無仮説の下で漸近標準正規分布に従います。標準化された検定統計量は次のように計算されます。
を使用します。この統計量は、カッパ係数がゼロであるという帰無仮説の下で漸近標準正規分布に従います。標準化された検定統計量は次のように計算されます。
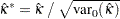 |
ここで、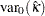 は、帰無仮説の下でのカッパ係数の分散です。
は、帰無仮説の下でのカッパ係数の分散です。
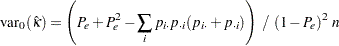 |
詳細は、Fleiss, Levin, and Paik (2003)を参照してください。
FREQプロシジャは、単純カッパ係数に関する正確な検定も提供します。この正確な検定を要求するには、EXACTステートメントでKAPPAまたはAGREEオプションを指定します。詳細は、正確な統計量のセクションを参照してください。
重み付きカッパ係数
重み付きカッパ係数は、単純カッパ係数の一般化であり、重みを使用してカテゴリ間の相対的差異を数値化します。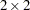 表の場合、重み付きカッパ係数は単純カッパ係数に等しくなります。FREQプロシジャは、より大きい表の場合にのみ、重み付きカッパ係数を表示します。FREQプロシジャは、次のセクションで説明されているCicchetti-Allison重みまたはFleiss-Cohen重みのいずれかを使用して、列スコアからカッパ係数の重みを計算します。重み
表の場合、重み付きカッパ係数は単純カッパ係数に等しくなります。FREQプロシジャは、より大きい表の場合にのみ、重み付きカッパ係数を表示します。FREQプロシジャは、次のセクションで説明されているCicchetti-Allison重みまたはFleiss-Cohen重みのいずれかを使用して、列スコアからカッパ係数の重みを計算します。重み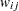 は、すべての
は、すべての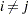 で
で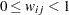 、すべての
、すべての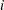 で
で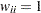 、および
、および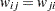 となるように構成されます。重み付きカッパ係数は次のように計算されます。
となるように構成されます。重み付きカッパ係数は次のように計算されます。
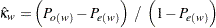 |
ここで、
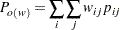 |
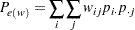 |
重み付きカッパ係数の漸近分散は次のようになります。
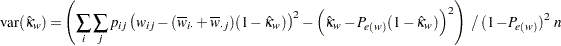 |
ここで、
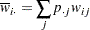 |
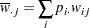 |
詳細は、Fleiss, Cohen, and Everitt (1969)を参照してください。
FREQプロシジャは、重み付きカッパ係数の信頼限界を次のように計算します。
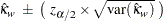 |
ここで、は標準正規分布の番目のパーセント点です。の値を指定するにはALPHA=オプションを使用します。この値はデフォルトで0.05であり、信頼限界は95%になります。
重み付きカッパ係数の漸近検定を計算する場合、FREQプロシジャは、標準化された検定統計量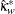 を使用します。この統計量は、重み付きカッパ係数がゼロであるという帰無仮説の下で漸近標準正規分布に従います。標準化された検定統計量は次のように計算されます。
を使用します。この統計量は、重み付きカッパ係数がゼロであるという帰無仮説の下で漸近標準正規分布に従います。標準化された検定統計量は次のように計算されます。
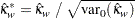 |
ここで、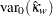 は、帰無仮説の下での重み付きカッパ係数の分散です。
は、帰無仮説の下での重み付きカッパ係数の分散です。
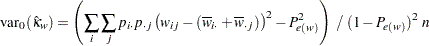 |
詳細は、Fleiss, Levin, and Paik (2003)を参照してください。
FREQプロシジャは、重み付きカッパ係数に関する正確な検定も提供します。この正確な検定を要求するには、EXACTステートメントでWTKAPPAまたはAGREEオプションを指定します。詳細は、正確な統計量のセクションを参照してください。
重み
FREQプロシジャは、列スコアと2つの利用可能な重みタイプのいずれかを使用して、カッパ係数の重みを計算します。列スコアは、TABLESステートメントのSCORES=オプションにより決定されます。2種類の利用可能な重みは、Cicchetti-Allisonの重みとFleiss-Cohenの重みになります。デフォルトでは、FREQプロシジャはCicchetti-Allisonの重みを使用します。AGREEオプションで(WT=FC)を指定すると、FREQプロシジャは、Fleiss-Cohenの重みを使用して重み付きカッパ係数を計算します。
FREQプロシジャは、Cicchetti-Allisonのカッパ係数重みを次のように計算します。
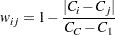 |
ここで、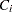 は列のスコア、
は列のスコア、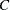 はカテゴリ数または列数です。詳細は、Cicchetti and Allison (1971)を参照してください。
はカテゴリ数または列数です。詳細は、Cicchetti and Allison (1971)を参照してください。
TABLESステートメントのSCORES=オプションは、カッパ係数の重み(およびその他のスコアに基づく統計量)の計算に使用される列スコアのタイプを指定します。デフォルトはSCORES=TABLEです。詳細は、スコアのセクションを参照してください。数値変数の場合、表スコアは、 行および列レベルの値となります。レベルの類似度を反映するように、各レベルに数値を割り当てることができます。たとえば、4つのレベルがあり、それらを類似度に基づいて順序付けるとします。それらの各レベルに値0、2、4、10を割り当てた場合、Cicchetti-Allisonのカッパ係数重みは、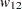 = 0.8、
= 0.8、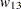 = 0.6、
= 0.6、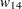 = 0、
= 0、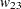 = 0.8、
= 0.8、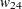 = 0.2、および
= 0.2、および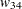 = 0.4になります。2つのカテゴリが存在する場合(すなわち、 = 2である場合)にのみ、重み付きカッパ係数は単純カッパ係数と同じになります。
= 0.4になります。2つのカテゴリが存在する場合(すなわち、 = 2である場合)にのみ、重み付きカッパ係数は単純カッパ係数と同じになります。
TABLESステートメントのAGREEオプションで(WT=FC)を指定すると、FREQプロシジャは、Fleiss-Cohenのカッパ係数重みを次のように計算します。
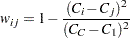 |
詳細は、Fleiss and Cohen (1973)を参照してください。
先述の例では、Fleiss-Cohenのカッパ係数重みは、 = 0.96、 = 0.84、 = 0、 = 0.96、 = 0.36、および = 0.64になります。
全体のカッパ係数
複数の層が存在する場合、FREQプロシジャは、カッパ係数の層レベルの推定値を組み合わせて、共通すると想定される値に対する全体のカッパ係数の推定値にします。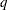 個の層が存在し、
個の層が存在し、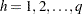 により添え字付けされるものとします。また、
により添え字付けされるものとします。また、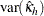 は
は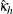 の分散を表すものとします。全体的なカッパ係数の推定値は次のように計算されます。
の分散を表すものとします。全体的なカッパ係数の推定値は次のように計算されます。
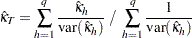 |
詳細は、Fleiss, Levin, and Paik (2003)を参照してください。
FREQプロシジャは、同じ方法により、全体的な重み付きカッパ係数の推定値も計算します。
カッパ係数が等しいかどうかの検定
複数の層が存在する場合、次のようなカイ2乗統計量により、カッパ係数の層レベル値が等しいかどうかを検定できます。
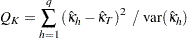 |
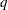 個の層でカッパ係数が等しいという帰無仮説の下で、
個の層でカッパ係数が等しいという帰無仮説の下で、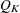 は自由度が
は自由度が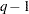 の漸近カイ2乗分布に従います。詳細は、Fleiss, Levin, and Paik (2003)を参照してください。FREQプロシジャは、同じ方法により、重み付きカッパ係数が等しいかどうかの検定も行います。
の漸近カイ2乗分布に従います。詳細は、Fleiss, Levin, and Paik (2003)を参照してください。FREQプロシジャは、同じ方法により、重み付きカッパ係数が等しいかどうかの検定も行います。
CochranのQ検定
Cochranのは、各変数が2つのレベルを持つ多次元クロス表、すなわち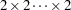 表に対して計算されます。Cochranの統計量は、1次元マージンの等質性の検定に使用されます。
表に対して計算されます。Cochranの統計量は、1次元マージンの等質性の検定に使用されます。 が変数の数を、
が変数の数を、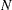 がサブジェクトの合計数を表すとします。Cochranの統計量は次のように計算されます。
がサブジェクトの合計数を表すとします。Cochranの統計量は次のように計算されます。
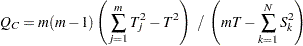 |
ここで、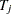 は変数
は変数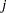 に関する肯定応答の数、
に関する肯定応答の数、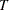 はすべての変数に関する肯定応答の数、
はすべての変数に関する肯定応答の数、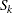 はサブジェクト
はサブジェクト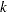 に関する肯定応答の数です。この帰無仮説の下では、Cochranのは自由度が
に関する肯定応答の数です。この帰無仮説の下では、Cochranのは自由度が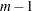 の漸近カイ2乗分布に従います。詳細はCochran (1950)を参照してください。2つの2値応答変数(
の漸近カイ2乗分布に従います。詳細はCochran (1950)を参照してください。2つの2値応答変数(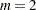 )のみが存在する場合、CochranのはMcNemar検定へと簡略化されます。複数の応答カテゴリが存在する場合、CATMODプロシジャの機能を繰り返し使用することで、周辺の等質性に関する検定を実施できます。
)のみが存在する場合、CochranのはMcNemar検定へと簡略化されます。複数の応答カテゴリが存在する場合、CATMODプロシジャの機能を繰り返し使用することで、周辺の等質性に関する検定を実施できます。
ゼロ行とゼロ列を含む表
各種のAGREE統計量は、列数が行数に等しい平方表に対してのみ定義されます。平方表でない表の場合、FREQプロシジャはAGREE統計量を計算しません。カッパ統計量の枠組みでは、2人の別々の評価者がサブジェクトのそれぞれにレーティングを割り当てます。ここでは、どちらの評価者が使用可能な のレーティングレベルをすべて使用しないと想定します。対応する表の行数がで列数は
のレーティングレベルをすべて使用しないと想定します。対応する表の行数がで列数は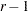 である場合、その表は平方表ではないため、この表に関してFREQプロシジャはAGREE統計量を計算しません。このような場合に平方表を作成するには、WEIGHTステートメントでZEROSオプションを指定します。これにより、FREQプロシジャは、重みがゼロのオブザベーションを分析に含めるようになります。評価者により使用されないレーティングレベルを表すには、重みがゼロのオブザベーションを入力データセットに含めます。これにより、この入力データセットに、評価者とレーティングの可能な組み合わせごとに少なくとも1つのオブザベーションが含まれます。この結果、実際には両評価者によりすべてのレベルが割り当てられていない場合であっても、分析にはすべてのレーティングレベルが含められます。結果として生成される表(評価者1×評価者2)は平方表であるため、AGREE統計量が計算されます。
である場合、その表は平方表ではないため、この表に関してFREQプロシジャはAGREE統計量を計算しません。このような場合に平方表を作成するには、WEIGHTステートメントでZEROSオプションを指定します。これにより、FREQプロシジャは、重みがゼロのオブザベーションを分析に含めるようになります。評価者により使用されないレーティングレベルを表すには、重みがゼロのオブザベーションを入力データセットに含めます。これにより、この入力データセットに、評価者とレーティングの可能な組み合わせごとに少なくとも1つのオブザベーションが含まれます。この結果、実際には両評価者によりすべてのレベルが割り当てられていない場合であっても、分析にはすべてのレーティングレベルが含められます。結果として生成される表(評価者1×評価者2)は平方表であるため、AGREE統計量が計算されます。
詳細は、ZEROSオプションの説明を参照してください。デフォルトでは、FREQプロシジャは、重みがゼロのオブザベーションを処理しません。なぜなら、これらのオブザベーションが合計度数に寄与しないために、結果として生成される重みゼロの行または列により連関性の検定や指標の多くが定義されなくなるためです。ただし、カッパ統計量は重みがゼロの行または列を含む表に対して定義されるため、ZEROSオプションを指定することで、重みがゼロのオブザベーションを入力し、カッパ係数の計算に必要となる表を構成できます。