UNIVARIATEプロシジャ
- 概要
-
入門ガイド

-
構文
-
詳細欠損値丸め記述統計量モードの計算パーセント点の計算位置の検定正規分布のパラメータに対する信頼限界ロバスト推定量ラインプリンタプロットの作成高解像度グラフの作成CLASSステートメントを使用した比較プロットの作成インセットの配置当てはめた連続分布の計算式適合度検定核密度推定Q-Qプロットと確率プロットの作成Q-Qプロットと確率プロットの解釈確率プロットとQ-Qプロットの分布Q-Qプロットを使用した形状パラメータの推定Q-Qプロットを使用した位置パラメータと尺度パラメータの推定Q-Qプロットを使用したパーセント点の推定入力データセットOUTPUTステートメントのOUT=出力データセットOUTHISTOGRAM=出力データセットOUTKERNEL=出力データセットOUTTABLE=出力データセット要約統計量のテーブルODSテーブル名当てはめた分布のODSテーブルODS Graphics計算リソース
-
例複数の変数に対する記述統計量の計算モードの計算極値オブザベーションと極値の表示度数表の作成基本要約プロットの作成FREQ変数を使用したデータセットの分析OUT=出力データセットへの要約統計量の保存出力データセットへのパーセント点の保存平均、標準偏差、分散に対する信頼限界の計算分位点とパーセント点に対する信頼限界の計算ロバスト推定の計算位置の検定ペアのデータを使用した符号検定の実行ヒストグラムの作成一元比較ヒストグラムの作成二元比較ヒストグラムの作成記述統計量を含むインセットの追加ヒストグラムのビン幅の指定正規曲線をヒストグラムに追加する当てはめた正規曲線を比較ヒストグラムに追加するベータ曲線の当てはめ対数正規曲線、Weibull曲線、ガンマ曲線の当てはめ核密度推定の計算3パラメータ対数正規曲線の当てはめ折り重ねられた正規曲線の追加表示対数正規確率プロットの作成対数正規分布の当てはめを表示するヒストグラムの作成正規分位点プロットの作成分布参照線の追加正規分位点プロットの解釈対数正規分位点プロットから3パラメータを推定する対数正規分位点プロットからパーセント点を推定する対数正規分位点プロットからパラメータを推定するWeibull分布の分位点プロットの比較累積分布プロットの作成P-Pプロットの作成
- リファレンス
KERNELオプションを使用すると、核密度推定をヒストグラムに重ねて表示できます。核密度推定を使用してデータ分布を平滑化すると、ヒストグラムを使用するよりも効率的に、ヒストグラムビンの選択またはサンプリングの変化によって隠される可能性のある特徴を識別できます。また、核密度推定は、プロセス分布が多峰性である場合も、パラメトリックな曲線の当てはめより効率的です。例4.23を参照してください。
核密度推定量の一般形は次のとおりです。
ここで、
-
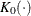 核関数
核関数
-
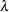 区間幅
区間幅
-
n 標本サイズ
-
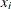 i番目のオブザベーション
i番目のオブザベーション
-
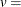 垂直比率
垂直比率
および
![\[ v = \left\{ \begin{array}{ll} n & \mbox{for VSCALE=COUNT} \\ 100 & \mbox{for VSCALE=PERCENT} \\ 1 & \mbox{for VSCALE=PROPORTION} \end{array} \right. \]](images/procstat_univariate0405.png)
KERNELオプションでは、正規、2次および3次の3つの核関数(![]() )を使用できます。関数は、KERNELオプションの後のかっこで囲んだK= kernel-optionで指定できます。K=オプションの値は、NORMAL、QUADRATICおよびTRIANGULAR (それぞれ、別名はN、QおよびT)です。デフォルトでは、正規核関数が使用されます。核関数の計算式は次のとおりです。
)を使用できます。関数は、KERNELオプションの後のかっこで囲んだK= kernel-optionで指定できます。K=オプションの値は、NORMAL、QUADRATICおよびTRIANGULAR (それぞれ、別名はN、QおよびT)です。デフォルトでは、正規核関数が使用されます。核関数の計算式は次のとおりです。
![\[ \begin{array}{lll} \mbox{Normal} & K_0(t) = \frac{1}{\sqrt {2\pi }} \exp (-\frac{1}{2}t^{2}) & \mbox{for } -\infty < t < \infty \\ \mbox{Quadratic} & K_0(t) = \frac{3}{4}(1-t^2) & \mbox{for } |t| \leq 1 \\ \mbox{Triangular} & K_0(t) = 1-|t| & \mbox{for } |t| \leq 1 \end{array} \]](images/procstat_univariate0407.png)
![]() の値は区間幅パラメータと呼ばれ、推定される密度関数の平滑度を決定します。
の値は区間幅パラメータと呼ばれ、推定される密度関数の平滑度を決定します。![]() は、C= kernel-optionで標準化区間幅cを指定することにより、間接的に指定します。Qが四分位範囲で、nが標本サイズの場合、cと
は、C= kernel-optionで標準化区間幅cを指定することにより、間接的に指定します。Qが四分位範囲で、nが標本サイズの場合、cと![]() には次の式で表される関係があります。
には次の式で表される関係があります。
特定の核関数では、密度推定量![]() と真密度
と真密度![]() の間のディスクレパンシは平均積分平方誤差(MISE)によって測定されます。
の間のディスクレパンシは平均積分平方誤差(MISE)によって測定されます。
MISEは、2乗バイアスの積分と分散の合計です。漸近的平均積分平方誤差(AMISE)は次のとおりです。
AMISEが最小になる区間幅は、![]() を、標本平均と標準偏差により推定されるパラメータ
を、標本平均と標準偏差により推定されるパラメータ![]() および
および![]() を持つ正規密度として扱うことにより導かれます。区間幅パラメータを指定しなかった場合またはC=MISEを指定した場合は、AMISEが最小になる区間幅が使用されます。AMISEの値を使用して、異なる密度推定を比較することができます。また、C=SJPIを指定すると、SheatherおよびJones (Jones, Marron, and Sheather; 1996)のプラグイン式を使用して、区間幅を選択できます。推定ごとに、区間幅パラメータc、核関数の種類およびAMISEの値が、SASログにレポートされます。
を持つ正規密度として扱うことにより導かれます。区間幅パラメータを指定しなかった場合またはC=MISEを指定した場合は、AMISEが最小になる区間幅が使用されます。AMISEの値を使用して、異なる密度推定を比較することができます。また、C=SJPIを指定すると、SheatherおよびJones (Jones, Marron, and Sheather; 1996)のプラグイン式を使用して、区間幅を選択できます。推定ごとに、区間幅パラメータc、核関数の種類およびAMISEの値が、SASログにレポートされます。
一般的な核密度推定は、推定する密度の定義域が実数直線上ですべての値を取り得ることを前提にしています。
しかし、密度の定義域が片側または両側で有界な間隔である場合があります。たとえば、変数Yが正の値のみの測定である場合、核密度曲線は負のY値に対して0になるように有界である必要があります。境界は、LOWER=およびUPPER= kernel-optionsで指定できます。
UNIVARIATEプロシジャは、Silverman (1986, pp. 30-31)の説明にあるように、反射法を使用して有界な核密度曲線を作成します。この方法では、境界の外側にある核密度の反射を、有界な核推定に追加します。
有界な核密度推定量の一般形は、元の等式の![]() を、次の式に置き換えることによって計算されます。
を、次の式に置き換えることによって計算されます。
ここで、![]() は下限、
は下限、![]() は上限です。
は上限です。
下限がない場合、![]() および
および![]() です。同様に、上限がない場合、
です。同様に、上限がない場合、![]() および
および![]() です。
です。
有界な核密度でC=MISEが使用されている場合、UNIVARIATEプロシジャは、非有界の核に対するAMISEが最小になる区間幅を使用します。