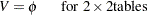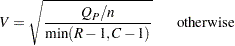FREQプロシジャ

カイ2乗検定と統計量
CHISQオプションは、等質性または独立性に対する各種のカイ2乗検定を実施し、特定のカイ2乗統計量に基づく連関性の指標を計算します。TABLESステートメント内でCHISQオプションを指定すると、FREQプロシジャは、各2元表に関して各種のカイ2乗検定(Pearsonカイ2乗、尤度比カイ2乗、Mantel-Haenszelのカイ2乗)を計算します。FREQプロシジャは、Pearsonカイ2乗統計量に基づく連関性の指標として、ファイ係数、一致係数、およびCramerの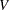 を計算します。
を計算します。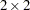 テーブルの場合、CHISQオプションを使用することで、Fisherの正確検定および連続修正を行ったカイ2乗検定を要求できます。一般的な
テーブルの場合、CHISQオプションを使用することで、Fisherの正確検定および連続修正を行ったカイ2乗検定を要求できます。一般的な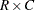 表に関してFisherの正確検定を要求するには、TABLESステートメントまたはEXACTステートメントでFISHERオプションを指定します。
表に関してFisherの正確検定を要求するには、TABLESステートメントまたはEXACTステートメントでFISHERオプションを指定します。
1元表の場合、CHISQを指定すると、カイ2乗適合度検定が行われます。このセクションで説明するその他のカイ2乗検定および統計量は、2元表に対してのみ計算されます。
本セクションで説明する2元表に対する検定統計量はすべて、行変数と列変数間に連関がないという帰無仮説をテストします。標本サイズ が大きい場合、帰無仮説が真であるならば、これらの検定統計量は漸近カイ2乗分布に従います。標本サイズが大きくない場合は、正確検定を使用します。FREQプロシジャは、Fisherの正確検定に加えて、Pearsonカイ2乗、尤度比カイ2乗、Mantel-Haenszelのカイ2乗に関する正確検定を行います。また、FREQプロシジャは、1元表に関するカイ2乗適合度検定も行います。これらの正確検定を要求するには、EXACTステートメントで対応するオプションを指定します。詳細は、正確な統計量のセクションを参照してください。
が大きい場合、帰無仮説が真であるならば、これらの検定統計量は漸近カイ2乗分布に従います。標本サイズが大きくない場合は、正確検定を使用します。FREQプロシジャは、Fisherの正確検定に加えて、Pearsonカイ2乗、尤度比カイ2乗、Mantel-Haenszelのカイ2乗に関する正確検定を行います。また、FREQプロシジャは、1元表に関するカイ2乗適合度検定も行います。これらの正確検定を要求するには、EXACTステートメントで対応するオプションを指定します。詳細は、正確な統計量のセクションを参照してください。
Mantel-Haenszelのカイ2乗統計量は、両変数が順序尺度である場合にのみ適用できます。本セクションで説明するその他のカイ2乗検定および統計量は、変数が名義尺度であれ順序尺度であれ適用できます。これ以降の各セクションでは、FREQがカイ2乗検定および統計量の計算に使用する各種の公式を示します。詳細は、Agresti (2007)、Stokes, Davis, and Koch (2000)、および各統計量の説明で言及されているリファレンスを参照してください。
1元表に対するカイ2乗検定
1元度数表の場合、TABLESステートメントでCHISQオプションを指定すると、カイ2乗適合度検定が行われます。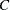 は、1元表内のクラス数またはレベル数を表すものとします。
は、1元表内のクラス数またはレベル数を表すものとします。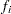 は、クラス
は、クラス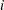 の度数(またはクラス内にあるオブザベーションの数)を表すものとします。ここで、
の度数(またはクラス内にあるオブザベーションの数)を表すものとします。ここで、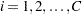 です。FREQプロシジャは、1元表に対するカイ2乗統計量を次の式により計算します。
です。FREQプロシジャは、1元表に対するカイ2乗統計量を次の式により計算します。
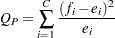 |
ここで、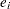 は、帰無仮説のもとでのクラスに関する期待度数です。
は、帰無仮説のもとでのクラスに関する期待度数です。
CHISQオプションのデフォルトである等比率に対する検定では、帰無仮説は、合計標本サイズに対する各クラスの比率が等しいとします。この帰無仮説のもとでは、各クラスの期待度数は、合計標本サイズをクラス数で割った値に等しくなります。
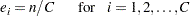 |
FREQプロシジャ で指定された度数の検定を計算する場合、TESTF=オプションを使用して帰無仮説の度数を入力すると、期待度数はTESTF=に指定された値になります。FREQプロシジャで指定された寄与率の検定を計算する場合、TESTP=オプションを使用して帰無仮説の寄与率を入力すると、 期待度数はTESTP=に指定された寄与率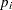 に基づいて次の式により決定されます。
に基づいて次の式により決定されます。
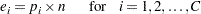 |
この帰無仮説(等しい寄与率、指定された度数、指定された寄与率を持つ)の下では、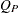 は自由度
は自由度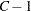 の漸近カイ2乗分布に従います。
の漸近カイ2乗分布に従います。
漸近検定に加えて、EXACTステートメントでCHISQオプションを指定すると、1元表に対する正確なカイ2乗検定を要求できます。詳細は、正確な統計量のセクションを参照してください。
2元表に対するPearsonカイ2乗検定
2元表に対するPearsonカイ2乗検定では、観測度数と期待度数間の差異を取り扱います。ここで、期待度数は、独立帰無仮説に基づいて計算されます。Pearsonカイ2乗統計量は次のように計算されます。
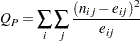 |
ここで、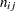 はテーブルセル(
はテーブルセル(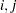 )の測定度数、
)の測定度数、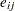 はテーブルセル()の期待度数です。期待度数は、行変数と列変数が独立であるという帰無仮説に基づいて計算されます。
はテーブルセル()の期待度数です。期待度数は、行変数と列変数が独立であるという帰無仮説に基づいて計算されます。
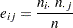 |
行変数と列変数が独立である場合、は自由度が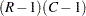 の漸近カイ2乗分布を持ちます。
の漸近カイ2乗分布を持ちます。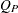 の値が大きい場合、この検定では帰無仮説ではなく、一般的な連関性に関する対立仮説を使用することを推奨します。
の値が大きい場合、この検定では帰無仮説ではなく、一般的な連関性に関する対立仮説を使用することを推奨します。
漸近検定に加えて、EXACTステートメントでPCHIオプションまたはCHISQオプションを指定すると、正確なPearsonカイ2乗検定を要求できます。詳細は、正確な統計量のセクションを参照してください。
表の場合、Pearsonカイ2乗を適用することで、2つの二項分布の割合が等しいかどうかも検定できます。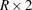 表や
表や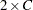 表の場合、Pearsonカイ2乗は寄与率の等質性を検定します。詳細はFienberg (1980)を参照してください。
表の場合、Pearsonカイ2乗は寄与率の等質性を検定します。詳細はFienberg (1980)を参照してください。
尤度比カイ2乗検定
尤度比カイ2乗検定では、観測度数と期待度数間の比を取り扱います。尤度比カイ2乗統計量は次のように計算されます。
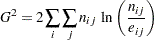 |
ここで、はテーブルセル()の測定度数、はテーブルセル()の期待度数です。
行変数と列変数が独立である場合、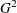 は自由度がの漸近カイ2乗分布を持ちます。
は自由度がの漸近カイ2乗分布を持ちます。
漸近検定に加えて、EXACTステートメントでLRCHIオプションまたはCHISQオプションを指定すると、正確な尤度比カイ2乗検定を要求できます。詳細は、正確な統計量のセクションを参照してください。
連続修正を行ったカイ2乗検定
表に対する連続修正を行ったカイ2乗検定は、Pearsonカイ2乗検定と同じになりますが、カイ2乗分布の連続性が補正される点が異なります。連続修正を行ったカイ2乗検定は、標本サイズが小さい場合に役立ちます。連続修正の使用に関しては議論が分かれることがありますが、標本サイズが小さい場合には、連続修正を行ったカイ2乗検定がより保守的となります(すなわち、よりFisherの正確検定に近づきます)。標本サイズが大きくなると、連続修正を行ったカイ2乗検定は、Pearsonカイ2乗検定により近づきます。
連続修正を行ったカイ2乗統計量は次のように計算されます。
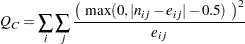 |
独立帰無仮説のもとでは、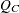 は、自由度がの漸近カイ2乗分布に従います。
は、自由度がの漸近カイ2乗分布に従います。
Mantel-Haenszelカイ2乗検定
Mantel-Haenszelカイ2乗統計量は、行変数と列変数間に線形連関性が存在するという対立仮説を検定します。両変数は順序尺度でなければなりません。Mantel-Haenszelカイ2乗統計量は次のように計算されます。
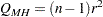 |
ここで、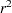 は、行変数と列変数間のPearson相関です。Pearson相関の詳細は、Pearsonの相関係数を参照してください。Pearsonの相関統計量およびMantel-Haenszelカイ2乗統計量は、TABLESステートメントのSCORES=オプションに指定されたスコアを使用します。詳細は、Mantel and Haenszel (1959)およびLandis, Heyman, and Koch (1978)を参照してください。
は、行変数と列変数間のPearson相関です。Pearson相関の詳細は、Pearsonの相関係数を参照してください。Pearsonの相関統計量およびMantel-Haenszelカイ2乗統計量は、TABLESステートメントのSCORES=オプションに指定されたスコアを使用します。詳細は、Mantel and Haenszel (1959)およびLandis, Heyman, and Koch (1978)を参照してください。
連関性がないという帰無仮説のもとでは、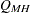 は、自由度が1の漸近カイ2乗分布に従います。
は、自由度が1の漸近カイ2乗分布に従います。
漸近検定に加えて、EXACTステートメントでMHCHIオプションまたはCHISQオプションを指定すると、正確なMantel-Haenszelカイ2乗検定を要求できます。詳細は、正確な統計量のセクションを参照してください。
Fisherの正確検定
Fisherの正確検定は、行変数と列変数間の連関性を検定する方法の1つです。この検定では、行と列の合計が固定されていると仮定した上で、超幾何分布を使用して観測された行および列合計の条件に応じて可能な表の確率を計算します。Fisherの正確検定は、いかなる標本サイズの大きな分布の仮定にも依存しないため、標本サイズの小さな分布や疎な分布に対しても適用できます。
2  2表
2表
表の場合、FREQプロシジャはFisherの正確検定に関する情報として、表確率、両側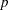 値、左側値、右側値を提供します。表確率は、観測された表の超幾何確率に等しくなります。これは、実際にはFisherの正確検定の検定統計量の値になります。
値、左側値、右側値を提供します。表確率は、観測された表の超幾何確率に等しくなります。これは、実際にはFisherの正確検定の検定統計量の値になります。
ここで、は、観測された行および列の合計を含む特定の表の超幾何確率です。Fisherの正確な値は、定義された表の集合に関して確率を合計することにより計算されます。
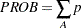 |
両側値は、観測された表確率以下のすべての可能な表の確率の合計(観測された行および列合計の条件に基づくもの)になります。両側値の場合、集合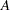 には、観測された表の確率以下の超幾何確率を持つすべての可能な表が含まれます。小さな両側値は、行変数と列変数間に連関性があるという対立仮説を支持します。
には、観測された表の確率以下の超幾何確率を持つすべての可能な表が含まれます。小さな両側値は、行変数と列変数間に連関性があるという対立仮説を支持します。
表の場合、Fisherの正確検定の片側値は、表の最初の行と最初の列にあるセル(1,1)の度数として定義されます。観測された(1,1)セルの度数を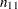 で表すと、Fisherの正確検定の左側値は、(1,1)セルの度数が以下である確率になります。左側値の場合、集合には、(1,1)セルの度数が以下である表が含まれます。小さな左側値は、オブザベーションが最初のセルに存在する確率が、行変数と列変数が独立であるという帰無仮説のもとで期待される確率よりも低いという対立仮説を支持します。
で表すと、Fisherの正確検定の左側値は、(1,1)セルの度数が以下である確率になります。左側値の場合、集合には、(1,1)セルの度数が以下である表が含まれます。小さな左側値は、オブザベーションが最初のセルに存在する確率が、行変数と列変数が独立であるという帰無仮説のもとで期待される確率よりも低いという対立仮説を支持します。
同様に、右側対立仮説では、は、セル(1,1)の度数が観測された同セルの度数以上である表の集合になります。小さい両側値は、最初のセルの確率が帰無仮説のもとでの期待確率よりも実際には大きいという対立仮説を支持します。
周辺行および列の合計が固定されている場合、(1,1)セルの度数が完全に表を決定するため、他のセルの確率やせる確率の比に関して、これらの片側対立仮説を等しく主張できます。左側対立仮説は、1未満のオッズ比に等しくなります。ここで、オッズ比は(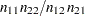 )です。また、左側対立仮説は、行1の列1リスクが行2の列1リスクよりも小さいこと(
)です。また、左側対立仮説は、行1の列1リスクが行2の列1リスクよりも小さいこと(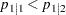 )に等しくなります。同様に、右側対立仮説は、行1の列1リスクが行2の列1リスクよりも大きいこと(
)に等しくなります。同様に、右側対立仮説は、行1の列1リスクが行2の列1リスクよりも大きいこと(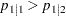 )に等しくなります。詳細はAgresti (2007)を参照してください。
)に等しくなります。詳細はAgresti (2007)を参照してください。
R C表
Fisherの正確検定は、Freeman and Halton (1951)により一般的な表へと拡張されました。この検定はFreeman-Halton検定とも呼ばれます。表の場合、両側値の定義は表の場合と同じになります。集合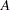 には、観測された表の確率以下の
には、観測された表の確率以下の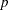 を持つすべての表が含まれます。小さな値は、行変数と列変数間に連関性があるという対立仮説を支持します。表の場合、Fisherの正確検定は本質的に両側検定となります。対立仮説は、リニアな連関性としてではなく、一般的な連関性としてのみ定義されます。このため、Fisherの正確検定は、一般的な表に関しては右側または左側値を持ちません。
を持つすべての表が含まれます。小さな値は、行変数と列変数間に連関性があるという対立仮説を支持します。表の場合、Fisherの正確検定は本質的に両側検定となります。対立仮説は、リニアな連関性としてではなく、一般的な連関性としてのみ定義されます。このため、Fisherの正確検定は、一般的な表に関しては右側または左側値を持ちません。
表の場合、FREQプロシジャは、Mehta and Patel (1983)のネットワークアルゴリズムを使用してFisherの正確検定を計算します。同アルゴリズムは、すべての組み合わせを列挙していく方法よりも高速で効率の良いソリューションを提供します。詳細は、正確な統計量のセクションを参照してください。
ファイ係数
ファイ係数は、Pearsonカイ2乗統計量から導かれる連関性の指標です。ファイ係数の範囲は、 表の場合、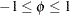 になります。より大きい表の場合、ファイ係数の範囲は
になります。より大きい表の場合、ファイ係数の範囲は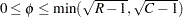 になります(Liebetrau 1983)。ファイ係数は次のように計算されます。
になります(Liebetrau 1983)。ファイ係数は次のように計算されます。
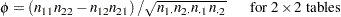 |
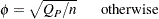 |
詳細は、Fleiss, Levin, and Paik (2003, pp. 98–99)を参照してください。
一致係数
一致係数は、Pearsonカイ2乗統計量から導かれる連関性の指標です。一致係数の範囲は、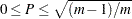 になります。ここで、
になります。ここで、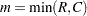 です(Liebetrau 1983)。一致係数は次のように計算されます。
です(Liebetrau 1983)。一致係数は次のように計算されます。
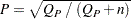 |
詳細は、Kendall and Stuart (1979, pp. 587–588)を参照してください。
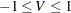 になります。
になります。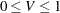 になります。Cramerの
になります。Cramerの