FREQプロシジャ

TABLESステートメントでRISKDIFFオプションを指定すると、![]() 表のリスク(二項比率)とリスク差の推定値を計算できます。この分析は、行1と行2が2つのグループに対応し、列が2つの可能な特性または結果に対応しているような2つのグループの特性を比較する場合に適しています。たとえば、行変数が処置または投薬量で、列変数が反応である場合などが挙げられます。詳細は、Collett
(1991)、Fleiss, Levin, and Paik (2003)、Stokes, Davis, and Koch (2012)を参照してください。
表のリスク(二項比率)とリスク差の推定値を計算できます。この分析は、行1と行2が2つのグループに対応し、列が2つの可能な特性または結果に対応しているような2つのグループの特性を比較する場合に適しています。たとえば、行変数が処置または投薬量で、列変数が反応である場合などが挙げられます。詳細は、Collett
(1991)、Fleiss, Levin, and Paik (2003)、Stokes, Davis, and Koch (2012)を参照してください。
![]() 表の度数が次のように表されるとします。
表の度数が次のように表されるとします。
|
列1 |
列2 |
合計 |
|
|
行1 |
|
|
|
|
行2 |
|
|
|
|
合計 |
|
|
N |
デフォルトでは、RISKDIFFオプションを指定すると、FREQプロシジャは、行1のリスク(比率)、行2のリスク、全体的なリスクの推定値、および![]() 表の列1と列2のリスク差を計算します。リスク差は、行1のリスクから行2のリスクを差し引いたものとして定義されます。リスクはこれらの行(行1、行2、または全体)の二項比率であり、それらの標準誤差および信頼限界の計算は、二項比率のセクションに示されている二項比率の計算方法に従います。
表の列1と列2のリスク差を計算します。リスク差は、行1のリスクから行2のリスクを差し引いたものとして定義されます。リスクはこれらの行(行1、行2、または全体)の二項比率であり、それらの標準誤差および信頼限界の計算は、二項比率のセクションに示されている二項比率の計算方法に従います。
行1の列1リスクは、列1に分類される行1オブザベーションの比率であり、次の式で表されます。
これは、行変数の第1水準における列1の反応の条件付き確率を推定します。行2の列1リスクは、列1に分類される行2オブザベーションの比率であり、次の式で表されます。
全体的な列1リスクは、列1に分類されるすべてのオブザベーションの比率であり、次の式で表されます。
列1のリスク差は2つの行のリスクを比較するものであり、行1の列1リスクから行2の列1リスクを差し引いたものとして計算されます。
行iの列1リスクの標準誤差は次のように計算されます。
全体的な列1リスクの標準誤差は次のように計算されます。
2つの行が独立した二項標本を表している場合、列1のリスク差の標準誤差は次のように計算されます。
列2のリスクとリスク差も同様に計算されます。
デフォルトでは、RISKDIFFオプションは、リスク(行1、行2、全体)およびリスク差のWald漸近信頼限界を計算します。デフォルトでは、RISKDIFFオプションは、リスクの正確な(Clopper-Pearson)信頼限界も計算します。この情報を表示しないようにするには、NORISKS riskdiff-optionを指定します。riskdiff-optionsを指定すると、リスク差の検定や別の種類の信頼限界を要求できます。詳細は、リスク差の信頼限界およびリスク差の検定の各セクションを参照してください。
各リスクは、それらの対応する行の二項比率に等しくなります。このセクションでは、RISKDIFFオプションを指定した場合にデフォルトで計算されるWald信頼限界について説明します。BINOMIALオプションを指定すると、リスク(二項比率)のその他の信頼限界の種類や検定も計算されます。詳細は、二項分布の信頼限界および二項検定の各セクションを参照してください。
Wald信頼限界は、二項分布の正規近似に基づきます。FREQプロシジャは、リスクとリスク差のWald信頼限界を次のように計算します。
ここで、Estは推定値、![]() は標準正規分布の
は標準正規分布の![]() 番目のパーセント点、
番目のパーセント点、![]() は推定値の標準誤差です。信頼水準
は推定値の標準誤差です。信頼水準![]() は、ALPHA=オプションにより定義されます。この値はデフォルトで0.05であり、95%の信頼限界を生成します。
は、ALPHA=オプションにより定義されます。この値はデフォルトで0.05であり、95%の信頼限界を生成します。
CORRECT riskdiff-optionを指定すると、FREQプロシジャは、リスクとリスク差の連続性補正Wald信頼限界を計算します。この連続性補正の目的は、正規近似と、離散型分布である二項分布との間の差異を調整することにあります。詳細は、Fleiss, Levin, and Paik (2003)を参照してください。連続性補正Wald信頼限界は次のように計算されます。
ここで、ccは連続性補正です。行1リスクの場合![]() 、行2リスクの場合
、行2リスクの場合![]() 、全体的なリスクの場合
、全体的なリスクの場合![]() 、リスク差の場合
、リスク差の場合![]() になります。列1および列2のリスクの場合、同じ連続性補正を使用します。
になります。列1および列2のリスクの場合、同じ連続性補正を使用します。
デフォルトでは、RISKDIFFオプションを指定すると、FREQプロシジャは、列1のリスク、列2のリスク、全体的なリスクの正確な(Clopper-Pearson)信頼限界も計算します。これらの信頼限界は、二項分布に基づく等尾部検定を反転することにより構成されます。詳細は、正確な(Clopper-Pearson)信頼限界のセクションを参照してください。
CL= riskdiff-optionを指定することで、リスク差のその他の信頼限界を要求できます。使用できる信頼限界の種類としては、Agresti-Caffo信頼限界、正確な条件なしの信頼限界、Hauck-Anderson信頼限界、Miettinen-Nurminen(スコア)信頼限界、Newcombe(ハイブリッドスコア)信頼限界、Wald信頼限界があります。連続性補正Newcombe信頼限界およびWald信頼限界も使用できます。
CL= riskdiff-optionにより生成される信頼限界の信頼係数は![]() %になります。ここで、
%になります。ここで、![]() の値はALPHA=オプションにより決定されます。デフォルトのALPHA=0.05は、95%の信頼限界を生成します。この信頼限界は、同等性、非劣性、優越性の検定により提供される検定ベースの信頼限界とは異なり、
の値はALPHA=オプションにより決定されます。デフォルトのALPHA=0.05は、95%の信頼限界を生成します。この信頼限界は、同等性、非劣性、優越性の検定により提供される検定ベースの信頼限界とは異なり、![]() %の信頼係数(Schuirmann, 1999)を持ちます。詳細は、リスク差の検定のセクションを参照してください。
%の信頼係数(Schuirmann, 1999)を持ちます。詳細は、リスク差の検定のセクションを参照してください。
正確な信頼限界の計算方法については、リスク差の正確な条件なしの信頼限界のセクションを参照してください。これらの信頼限界は、2つの個々の片側検定(裾を用いる手法)を反転して求められます。デフォルトでは、検定は標準化されていないリスク差に基づきます。RISKDIFF(METHOD=SCORE)オプションを指定すると、検定はスコア統計量に基づくようになります。
次のセクションでは、リスク差のAgresti-Coull信頼限界、Hauck-Anderson信頼限界、Miettinen-Nurminen(スコア)信頼限界、Newcombe(ハイブリッドスコア)信頼限界、Wald信頼限界の計算方法について説明します。
Agresti-Caffo信頼限界 リスク差のAgresti-Caffo信頼限界は、次のように計算されます。
ここで、![]() ,
, ![]()
![]() は、標準正規分布の
は、標準正規分布の![]() 番目のパーセント点です。
番目のパーセント点です。
Agresti-Caffo区間は、各標本の種類(成功と失敗)ごとに疑似オブザベーションを追加することで、リスク差のWald区間を調整します。詳細については、Agresti and Caffo (2000)およびAgresti and Coull (1998)を参照してください。
Hauck-Anderson信頼限界 リスク差のHauck-Anderson信頼限界は次のように計算されます。
ここで、![]() であり、
であり、![]() は標準正規分布の
は標準正規分布の![]() 番目のパーセント点です。標準誤差は、標本比率から次のように計算されます。
番目のパーセント点です。標準誤差は、標本比率から次のように計算されます。
Hauck-Anderson連続性補正ccは次のように計算されます。
詳細は、Hauck and Anderson (1986)を参照してください。対応する非劣性の検定については、セクション非劣性の検定内のサブセクション"Hauck-Anderson検定"を参照してください。
Miettinen-Nurminen (スコア)信頼限界 リスク差のMiettinen-Nurminen (スコア)信頼限界(Miettinen and Nurminen, 1985)は、リスク差のスコア検定を反転することにより計算されます。リスク差が![]() に等しいという帰無仮説に対するスコアに基づく検定統計量は、次のように表されます。
に等しいという帰無仮説に対するスコアに基づく検定統計量は、次のように表されます。
ここで、![]() はリスク差(
はリスク差(![]() )の観測値です。
)の観測値です。
ここで、![]() および
および![]() は、リスク差が
は、リスク差が![]() であるという制限の下での行1と行2のリスク(比率)の最尤推定値です。詳細は、Miettinen and Nurminen (1985, pp. 215–216)およびMiettinen (1985, chapter 12)を参照してください。
であるという制限の下での行1と行2のリスク(比率)の最尤推定値です。詳細は、Miettinen and Nurminen (1985, pp. 215–216)およびMiettinen (1985, chapter 12)を参照してください。
リスク差の![]() %の信頼区間は、スコア統計量
%の信頼区間は、スコア統計量![]() が選択域に入る、
が選択域に入る、![]() のすべての値により構成されます。
のすべての値により構成されます。
ここで、![]() は、標準正規分布の
は、標準正規分布の![]() 番目のパーセント点です。FREQプロシジャは、反復計算により信頼限界を求めます。この計算は、反復の増分が収束基準を下回った場合か、または最大反復回数に達した場合に停止します。デフォルトでは、収束基準は0.00000001であり、 最大反復回数は100です。
番目のパーセント点です。FREQプロシジャは、反復計算により信頼限界を求めます。この計算は、反復の増分が収束基準を下回った場合か、または最大反復回数に達した場合に停止します。デフォルトでは、収束基準は0.00000001であり、 最大反復回数は100です。
デフォルトでは、Miettinen-Nurminen信頼限界は、バイアス補正因子![]() を
を![]() の計算に含めます(Miettinen and Nurminen, 1985, p. 216)。詳細は、Newcombe and Nurminen (2011)を参照してください。CL=MN(CORRECT=NO) riskdiff-optionを指定すると、FREQプロシジャは、この計算にバイアス補正因子を含めません(Mee, 1984)。Agresti (2002, p. 77)も参照してください。無修正の信頼限界は、表示出力において“Miettinen-Nurminen-Mee”としてラベル付けされます。
の計算に含めます(Miettinen and Nurminen, 1985, p. 216)。詳細は、Newcombe and Nurminen (2011)を参照してください。CL=MN(CORRECT=NO) riskdiff-optionを指定すると、FREQプロシジャは、この計算にバイアス補正因子を含めません(Mee, 1984)。Agresti (2002, p. 77)も参照してください。無修正の信頼限界は、表示出力において“Miettinen-Nurminen-Mee”としてラベル付けされます。
リスク差が![]() であるという制約を受けた、
であるという制約を受けた、![]() および
および![]() の最尤推定値は、次のように計算されます。
の最尤推定値は、次のように計算されます。
ここで、
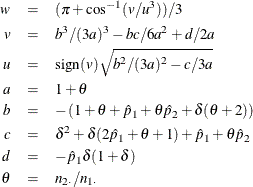
詳細は、Farrington and Manning (1990, p. 1453)を参照してください。
Newcombe信頼限界 リスク差のNewcombe (ハイブリッドスコア)信頼限界は、2つの個別比率のそれぞれのWilsonスコア信頼限界から構成されます。個別比率の信頼限界は、比率差のWald信頼限界の標準誤差項目として使用されます。詳細は、Newcombe (1998a)およびBarker et al. (2001)を参照してください。
![]() および
および![]() のWilson信頼限界は次の根になります。
のWilson信頼限界は次の根になります。
ここで、![]() です。信頼限界は次のように計算されます。
です。信頼限界は次のように計算されます。
詳細は、Wilson (スコア)信頼限界のセクションを参照してください。
![]() の下側および上側のWilsonスコア信頼限界を
の下側および上側のWilsonスコア信頼限界を![]() および
および![]() で表し、
で表し、![]() の下側および上側のWilsonスコア信頼限界を
の下側および上側のWilsonスコア信頼限界を![]() および
および![]() で表します。比率の差(
で表します。比率の差(![]() )のNewcombe信頼限界は次のように計算されます。
)のNewcombe信頼限界は次のように計算されます。
![\begin{eqnarray*} d_ L = (\hat{p}_1 - \hat{p}_2) ~ - ~ \sqrt { ( \hat{p}_1 - L_1 )^2 ~ +~ ( U_2 - \hat{p}_2 )^2 } \\[0.10in] d_ U = (\hat{p}_1 - \hat{p}_2) ~ + ~ \sqrt { ( U_1 - \hat{p}_1 )^2 ~ +~ ( \hat{p}_2 - L_2 )^2 } \end{eqnarray*}](images/procstat_freq0325.png)
CORRECT riskdiff-optionを指定すると、FREQプロシジャは、連続性補正Newcombeスコア信頼限界を計算します。連続性補正![]() を含めることにより、個別比率のWilsonスコア信頼限界は次の根として計算されます。
を含めることにより、個別比率のWilsonスコア信頼限界は次の根として計算されます。
続いて、個別比率の連続性補正信頼限界を使用して、比率差の信頼限界![]() および
および![]() が計算されます。
が計算されます。
Wald信頼限界 リスク差のWald信頼限界は次のように計算されます。
ここで、![]() であり、
であり、![]() は標準正規分布の
は標準正規分布の![]() 番目のパーセント点でし。標準誤差は、標本比率から次のように計算されます。
番目のパーセント点でし。標準誤差は、標本比率から次のように計算されます。
CORRECT riskdiff-optionを指定すると、Wald信頼限界に連続性補正ccが含まれます。
ここで、![]() です。
です。
riskdiff-optionsを指定すると、リスク(比率)の差異の検定を要求できます。要求できる検定としては、リスク差の等価性、非劣性、優越性、同等性の検定があります。等価性の検定は、連続性補正ありまたは連続性補正なしの標準Wald漸近検定になります。リスク差の非劣性、優越性、同等性の検定では、検定方式として、Wald検定(連続性補正ありまたは連続性補正なし)検定、Hauck-Anderson検定、Farrington-Manning(スコア)検定、Newcombe(連続性補正ありまたは連続性補正なし)検定が使用できます。検定方法を指定するには、METHOD= riskdiff-optionを使用します。デフォルトでは、FREQプロシジャはMETHOD=WALDを使用します。
EQUAL riskdiff-optionを指定すると、FREQプロシジャは等価性の検定、すなわちリスク差がゼロに等しいという帰無仮説の下での検定を計算します。列1(または列2)のリスク差の場合、この検定は帰無仮説![]() および対立仮説
および対立仮説![]() で表されます。ここで、
で表されます。ここで、![]() は列1(または列2)のリスク差を表します。FREQプロシジャは、等価性のWald漸近検定を計算します。検定統計量は次のように計算されます。
は列1(または列2)のリスク差を表します。FREQプロシジャは、等価性のWald漸近検定を計算します。検定統計量は次のように計算されます。
デフォルトでは、標準誤差は、標本比率から次のように計算されます。
VAR=NULL riskdiff-optionを指定すると、行1と行2のリスクが等しいという帰無仮説に基づいて標準誤差が次のように計算されます。
ここで、![]() は全体的な列1リスクの推定値です。
は全体的な列1リスクの推定値です。
CORRECT riskdiff-optionを指定すると、FREQプロシジャは、検定統計量に連続性補正を含めます。![]() である場合、連続性補正は、検定統計量の分子の
である場合、連続性補正は、検定統計量の分子の![]() から差し引かれます。それ以外の場合、連続性補正は同分子に追加されます。連続性補正値は
から差し引かれます。それ以外の場合、連続性補正は同分子に追加されます。連続性補正値は![]() になります。
になります。
FREQプロシジャは、この検定の片側および両側のp値を計算します。検定統計量zがゼロより大きい場合、FREQプロシジャは、右側のp値を表示します。これは、帰無仮説の下でより大きい値が発生する確率を表します。片側のp値は次のように計算されます。
ここで、Zは標準正規分布に従います。両側のp値は、![]() として計算されます。
として計算されます。
NONINF riskdiff-optionを指定すると、FREQプロシジャはリスク差、すなわち2つの比率間の差の非劣性の検定を実施します。非劣性の検定の帰無仮説は、次のようになります。
対立仮説は次のようになります。
ここで、![]() は非劣性マージンです。帰無仮説の棄却は、行1のリスクが行2のリスクに対して劣性でないことを示します。詳細は、Chow, Shao, and Wang (2003)を参照してください。
は非劣性マージンです。帰無仮説の棄却は、行1のリスクが行2のリスクに対して劣性でないことを示します。詳細は、Chow, Shao, and Wang (2003)を参照してください。
![]() の値を指定するには、MARGIN= riskdiff-optionを使用します。デフォルトでは
の値を指定するには、MARGIN= riskdiff-optionを使用します。デフォルトでは![]() です。検定方法を指定するには、METHOD= riskdiff-optionを使用します。リスク差の非劣性の分析では、検定方式として、Wald検定(連続性補正ありまたは連続性補正なし)検定、Hauck-Anderson検定、Farrington-Manning(スコア)検定、Newcombe検定(連続性補正ありまたは連続性補正なし)が使用できます。Wald、Hauck-Anderson、Farrington-Manningの各方式は、検定および対応する信頼限界を提供します。Newcombe方式は、信頼限界のみを提供します。METHOD=を省略すると、FREQプロシジャはデフォルトでWald検定を使用します。
です。検定方法を指定するには、METHOD= riskdiff-optionを使用します。リスク差の非劣性の分析では、検定方式として、Wald検定(連続性補正ありまたは連続性補正なし)検定、Hauck-Anderson検定、Farrington-Manning(スコア)検定、Newcombe検定(連続性補正ありまたは連続性補正なし)が使用できます。Wald、Hauck-Anderson、Farrington-Manningの各方式は、検定および対応する信頼限界を提供します。Newcombe方式は、信頼限界のみを提供します。METHOD=を省略すると、FREQプロシジャはデフォルトでWald検定を使用します。
検定に基づく信頼限界の信頼係数は![]() %です(Schuirmann, 1999)。ALPHA=を省略すると、これらはデフォルトで90%の信頼限界になります。この信頼限界を非劣性の限界–
%です(Schuirmann, 1999)。ALPHA=を省略すると、これらはデフォルトで90%の信頼限界になります。この信頼限界を非劣性の限界–![]() と比較できます。
と比較できます。
次のセクションでは、リスク差の非劣性の各種の分析方式について説明します。
Wald検定 METHOD=WALD riskdiff-optionを指定すると、FREQプロシジャはリスク差の非劣性の漸近Wald検定を実施します。これはデフォルトの分析方式でもあります。Wald検定統計量は次のように計算されます。
ここで、(![]() )はリスク差の推定値であり、
)はリスク差の推定値であり、![]() は非劣性のマージンです。
は非劣性のマージンです。
デフォルトでは、Wald検定の標準誤差は、標本比率から次のように計算されます。
VAR=NULL riskdiff-optionを指定すると、標準誤差は、リスク差が–![]() に等しいという帰無仮説に基づきます(Dunnett and Gent, 1977)。標準誤差は次のように計算されます。
に等しいという帰無仮説に基づきます(Dunnett and Gent, 1977)。標準誤差は次のように計算されます。
ここで、
CORRECT riskdiff-optionを指定すると、検定統計量に連続性補正が含められます。連続性補正は、検定統計量の分子が正数である場合、同分子から差し引かれます。それ以外の場合、連続性補正は同分子に追加されます。連続性補正値は![]() になります。
になります。
Wald非劣性の検定のp値は![]() であり、ここでZは標準正規分布に従います。
であり、ここでZは標準正規分布に従います。
Hauck-Anderson検定 METHOD=HA riskdiff-optionを指定すると、FREQプロシジャは非劣性のHauck-Anderson検定を行います。Hauck-Anderson検定統計量は次のように計算されます。
ここで、![]() であり、標準誤差は標本比率から次のように計算されます。
であり、標準誤差は標本比率から次のように計算されます。
Hauck-Anderson連続性補正ccは次のように計算されます。
非劣性のHauck-Anderson検定のp値は![]() であり、ここでZは標準正規分布に従います。詳細は、Hauck and Anderson (1986)およびSchuirmann (1999)を参照してください。
であり、ここでZは標準正規分布に従います。詳細は、Hauck and Anderson (1986)およびSchuirmann (1999)を参照してください。
Farrington-Manning (スコア)検定 METHOD=FM riskdiff-optionを指定すると、FREQプロシジャはリスク差の非劣性のFarrington-Manning(スコア)検定を実施します。リスク差が–![]() に等しいという帰無仮説に対するスコア検定統計量は、次のように表されます。
に等しいという帰無仮説に対するスコア検定統計量は、次のように表されます。
ここで、![]() はリスク差(
はリスク差(![]() )の観測値です。
)の観測値です。
ここで、![]() および
および![]() は、リスク差が–
は、リスク差が–![]() であるという制限の下での行1と行2のリスク(比率)の最尤推定値です。非劣性の検定のp値は
であるという制限の下での行1と行2のリスク(比率)の最尤推定値です。非劣性の検定のp値は![]() であり、ここでZは標準正規分布に従います。詳細は、Miettinen and Nurminen (1985)、Miettinen (1985)、Farrington and Manning (1990)、Dann and Koch (2005)を参照してください。
であり、ここでZは標準正規分布に従います。詳細は、Miettinen and Nurminen (1985)、Miettinen (1985)、Farrington and Manning (1990)、Dann and Koch (2005)を参照してください。
リスク差が–![]() であるという制約を受けた、
であるという制約を受けた、![]() および
および![]() の最尤推定値は、次のように計算されます。
の最尤推定値は、次のように計算されます。
ここで、
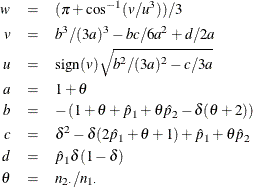
詳細は、Farrington and Manning (1990, p. 1453)を参照してください。
Newcombe非劣性分析 METHOD=NEWCOMBE riskdiff-optionを指定すると、FREQプロシジャは、リスク差のNewcombeハイブリッドスコア信頼限界に基づいた非劣性の分析を実施します。
この信頼限界の信頼係数は![]() %になります(Schuirmann, 1999)。ALPHA=を省略すると、これらはデフォルトで90%の信頼限界になります。この信頼限界を非劣性の限界–
%になります(Schuirmann, 1999)。ALPHA=を省略すると、これらはデフォルトで90%の信頼限界になります。この信頼限界を非劣性の限界–![]() と比較できます。CORRECT riskdiff-optionを指定すると、信頼限界に連続性補正が含められます。詳細は、セクションリスク差の信頼限界内のサブセクション"Newcombe信頼限界"を参照してください。
と比較できます。CORRECT riskdiff-optionを指定すると、信頼限界に連続性補正が含められます。詳細は、セクションリスク差の信頼限界内のサブセクション"Newcombe信頼限界"を参照してください。
SUP riskdiff-optionを指定すると、FREQプロシジャは、リスク差の優越性の検定を実施します。帰無仮説は次のようになります。
対立仮説は次のようになります。
ここで、![]() は優越性のマージンです。帰無仮説の棄却は、行1の比率が行2の比率に対して優越していることを示します。
は優越性のマージンです。帰無仮説の棄却は、行1の比率が行2の比率に対して優越していることを示します。![]() の値を指定するには、MARGIN= riskdiff-optionを使用します。デフォルトでは、
の値を指定するには、MARGIN= riskdiff-optionを使用します。デフォルトでは、![]() です。
です。
優越性の分析は非劣性分析と同じですが、帰無仮説で正のマージン値![]() を使用するところが違います。優越性の計算は非劣性の検定のセクションに示されている方法に従いますが、–
を使用するところが違います。優越性の計算は非劣性の検定のセクションに示されている方法に従いますが、–![]() の代わりに
の代わりに![]() を使用します。詳細は、Chow, Shao, and Wang (2003)を参照してください。
を使用します。詳細は、Chow, Shao, and Wang (2003)を参照してください。
EQUIV riskdiff-optionを指定すると、FREQプロシジャはリスク差、すなわち2つの比率間の差の同等性の検定を実施します。同等性の検定の帰無仮説は次のようになります。
対立仮説は次のようになります。
ここで、![]() は下限マージン、
は下限マージン、![]() は上限マージンです。帰無仮説の棄却は、2つの二項比率が等しいことを示します。詳細は、Chow, Shao, and Wang (2003)を参照してください。
は上限マージンです。帰無仮説の棄却は、2つの二項比率が等しいことを示します。詳細は、Chow, Shao, and Wang (2003)を参照してください。
マージン値![]() および
および![]() を指定するには、MARGIN= riskdiff-optionを使用します。MARGIN=を指定しない場合、FREQプロシジャはデフォルトの下限マージンおよび上限マージンとして、それぞれ–0.2および0.2を使用します。単一のマージン値
を指定するには、MARGIN= riskdiff-optionを使用します。MARGIN=を指定しない場合、FREQプロシジャはデフォルトの下限マージンおよび上限マージンとして、それぞれ–0.2および0.2を使用します。単一のマージン値![]() を指定すると、FREQプロシジャは下限マージンおよび上限マージンとして、それぞれ–
を指定すると、FREQプロシジャは下限マージンおよび上限マージンとして、それぞれ–![]() および
および![]() を使用します。検定方法を指定するには、METHOD= riskdiff-optionを使用します。リスク差の同等性分析では、検定方式として、Wald(連続性補正ありまたは連続性補正なし)検定、Hauck-Anderson検定、Farrington-Manning(スコア)検定、Newcombe検定(連続性補正ありまたは連続性補正なし)が使用できます。Wald、Hauck-Anderson、Farrington-Manningの各方式は、検定および対応する信頼限界を提供します。Newcombe方式は、信頼限界のみを提供します。METHOD=を省略すると、FREQプロシジャはデフォルトでWald検定を使用します。
を使用します。検定方法を指定するには、METHOD= riskdiff-optionを使用します。リスク差の同等性分析では、検定方式として、Wald(連続性補正ありまたは連続性補正なし)検定、Hauck-Anderson検定、Farrington-Manning(スコア)検定、Newcombe検定(連続性補正ありまたは連続性補正なし)が使用できます。Wald、Hauck-Anderson、Farrington-Manningの各方式は、検定および対応する信頼限界を提供します。Newcombe方式は、信頼限界のみを提供します。METHOD=を省略すると、FREQプロシジャはデフォルトでWald検定を使用します。
FREQプロシジャは、同等性の分析で、2つの片側検定(TOST)を計算します(Schuirmann, 1987)。TOST手法には、下限マージン![]() の右側検定と、上限マージン
の右側検定と、上限マージン![]() の左側検定が含まれます。全体的なp値は、下側および上側の検定における2つのp値のうちの大きい方になります。
の左側検定が含まれます。全体的なp値は、下側および上側の検定における2つのp値のうちの大きい方になります。
リスク差のWald、Hauck-Anderson、Farrington-Manning (スコア)、Newcombeの各検定についての詳細は、非劣性の検定のセクションを参照してください。下限マージンの同等性の検定統計量は、非劣性の検定統計量と同じ形式を持ちますが、前者は-![]() のかわりに下限マージン値
のかわりに下限マージン値![]() を使用します。上限マージンの同等性の検定統計量は、非劣性の検定統計量と同じ形式を持ちますが、前者は-
を使用します。上限マージンの同等性の検定統計量は、非劣性の検定統計量と同じ形式を持ちますが、前者は-![]() のかわりに上限マージン値
のかわりに上限マージン値![]() を使用します。
を使用します。
リスク差の検定ベースの信頼限界は、ユーザーが選択した同等性の検定方式に従って計算されます。
METHOD=WALDと共にVAR=NULLまたはMETHOD=FMを指定すると、下限および上限マージン検定の標準誤差が別々に計算されます。この場合、検定ベースの信頼限界は、これらの標準誤差の最大値を使用して計算されます。これらの信頼限界の信頼係数は![]() %になります(Schuirmann, 1999)。ALPHA=を省略すると、これらはデフォルトで90%の信頼限界になります。検定ベースの信頼限界を同等性の限界
%になります(Schuirmann, 1999)。ALPHA=を省略すると、これらはデフォルトで90%の信頼限界になります。検定ベースの信頼限界を同等性の限界![]() と比較できます。
と比較できます。
EXACTステートメントでRISKDIFFオプションを指定すると、FREQプロシジャは、リスク差の正確な条件なしの信頼限界を計算します。FREQプロシジャは、2つの個々の片側検定(裾を用いる手法)を反転して、信頼限界を計算します。ここで、各検定のサイズは最大で![]() であり、信頼係数は最低でも
であり、信頼係数は最低でも![]() になります。正確な条件付き方式(セクション正確な統計量を参照)は、撹乱パラメータが存在するため、リスク差には適用できません(Agresti, 1992)。条件なしの手法では、すべての可能な値に関してp値を最大化することで、撹乱パラメータを廃止しています(Santner and Snell, 1980)。
になります。正確な条件付き方式(セクション正確な統計量を参照)は、撹乱パラメータが存在するため、リスク差には適用できません(Agresti, 1992)。条件なしの手法では、すべての可能な値に関してp値を最大化することで、撹乱パラメータを廃止しています(Santner and Snell, 1980)。
デフォルトでは、FREQプロシジャは、信頼限界の計算における検定統計量として、標準化されていないリスク差を使用します。 RISKDIFF(METHOD=SCORE)オプションを指定すると、同プロシジャはスコア統計量を使用します(Chan and Zhang, 1999)。スコア統計量は生のリスク差よりも離散的でない統計量であるため、より保守的でない信頼限界を生成します(Agresti and Min, 2001)。リスク差の正確な信頼限界の計算方法の比較については、Santner et al. (2007)も参照してください。
FREQは次の信頼限界を計算します。リスク差は、行1と行2のリスク(比率)間の差![]() として定義されます。ここで、
として定義されます。ここで、![]() および
および![]() は
は![]() 表の行合計を表します。この表の結合確率関数は、表のセル度数、リスク差、撹乱パラメータ
表の行合計を表します。この表の結合確率関数は、表のセル度数、リスク差、撹乱パラメータ![]() を使って次のように表されます。
を使って次のように表されます。
リスク差の![]() %の信頼限界は次のように計算されます。
%の信頼限界は次のように計算されます。
ここで、
![\begin{eqnarray*} P_ U(d_\ast ) & = & \sup _{p_2} ~ \bigl ( \sum _{A, T(a) \geq t_0} f( n_{11}, n_{21}; n_1, n_2, d_\ast , p_2 ) ~ \bigr ) \\[0.10in] P_ L(d_\ast ) & = & \sup _{p_2} ~ \bigl ( \sum _{A, T(a) \leq t_0} f( n_{11}, n_{21}; n_1, n_2, d_\ast , p_2 ) ~ \bigr ) \end{eqnarray*}](images/procstat_freq0361.png)
集合Aには、行合計が![]() および
および![]() であるすべての
であるすべての![]() 表が含まれており、
表が含まれており、![]() はAにおける表aの検定統計量の値を表します。
はAにおける表aの検定統計量の値を表します。![]() を計算する場合、(
を計算する場合、(![]() )である表の確率が合計に含まれます。ここで、
)である表の確率が合計に含まれます。ここで、![]() は観測された表の検定統計量の値です。
は観測された表の検定統計量の値です。![]() が固定値の場合、
が固定値の場合、![]() は、
は、![]() のすべての可能な値の最大合計値となるように取得されます。
のすべての可能な値の最大合計値となるように取得されます。
デフォルトでは、FREQプロシジャは、標準化されていないリスク差を検定統計量Tとして使用します。RISKDIFF(METHOD=SCORE)オプションを指定すると、同プロシジャはリスク差のスコア統計量を検定統計量として使用します(Chan and Zhang, 1999)。スコア統計量の計算については、リスク差の信頼限界のセクションを参照してください。詳細は、Miettinen and Nurminen (1985)およびFarrington and Manning (1990)を参照してください。
EXACTステートメントのBARNARDオプションを指定すると、![]() 表のリスク(比率)の差に対して条件なしの正確検定が実施されます。条件なしの正確検定の参照集合は、観測された表と同じ行合計を含んでいるすべての
表のリスク(比率)の差に対して条件なしの正確検定が実施されます。条件なしの正確検定の参照集合は、観測された表と同じ行合計を含んでいるすべての![]() 表から構成されます(Barnard, 1945, 1947, 1949)。これは、正確な条件付きの推定の参照集合とは異なります。後者は、観測された表と同じ行合計および同じ列合計を含んでいる表の集合に限定されます。詳細は、Fisherの正確検定および正確な統計量のセクションを参照してください。
表から構成されます(Barnard, 1945, 1947, 1949)。これは、正確な条件付きの推定の参照集合とは異なります。後者は、観測された表と同じ行合計および同じ列合計を含んでいる表の集合に限定されます。詳細は、Fisherの正確検定および正確な統計量のセクションを参照してください。
この検定統計量は標準化されたリスク差であり、次のように計算されます。
ここで、リスク差dは、行1と行2のリスク(比率)間の差![]() として定義されます。
として定義されます。![]() および
および![]() は、それぞれ行1および行2の合計です。
は、それぞれ行1および行2の合計です。![]() は、列1における全体的な比率
は、列1における全体的な比率![]() です。
です。
リスク差がゼロに等しいという帰無仮説の下で、表の結合確率関数は、表のセル度数、行合計、未知のパラメータ![]() を使って次のように表されます。
を使って次のように表されます。
ここで、![]() はリスク(比率)の共通値です。
はリスク(比率)の共通値です。
FREQプロシジャは、 観測された検定統計量値以上の検定統計量を持つ表の参照集合に関する表確率を合計します。この合計は次のように表されます。
ここで、集合Aには、行合計が![]() および
および![]() であるすべての
であるすべての![]() 表が含まれており、
表が含まれており、![]() はAにおける表aの検定統計量の値を表します。合計には、(
はAにおける表aの検定統計量の値を表します。合計には、(![]() )である表の確率が含まれます。ここで、
)である表の確率が含まれます。ここで、![]() は、観測された表の検定統計量の値です。
は、観測された表の検定統計量の値です。
Prob(![]() )合計は、未知の値
)合計は、未知の値![]() により異なります。正確なp値を計算する場合、FREQプロシジャは、すべての可能な
により異なります。正確なp値を計算する場合、FREQプロシジャは、すべての可能な![]() の値に関してProb(
の値に関してProb( ![]() )の値を最大化することで、攪乱パラメータ
)の値を最大化することで、攪乱パラメータ![]() を廃止します。
を廃止します。
詳細は、Suissa and Shuster (1985)およびMehta and Senchaudhuri (2003)を参照してください。